C++调用mask rcnn进行实时检测--opencv4.0
介绍
Opencv在前面的几个版本中已经支持caffe、tensorflow、pytorch训练的几种模型,包括分类和物体检测模型(SSD、Yolo),针对tensorflow,opencv与tensorflow object detection api对接,可以通过该api训练模型,然后通过opencv调用,这样就可以把python下的环境移植到C++中。
关于tensorflow object detection api,后面博文会详细介绍
数据准备与环境配置
基于mask_rcnn_inception_v2_coco_2018_01_28的frozen_inference_graph.pb,这个模型在tensorflow object detection api中可以找到,然后需要对应的mask_rcnn_inception_v2_coco_2018_01_28.pbtxt,以及colors.txt,mscoco_labels.names。
opencv必须是刚发布的4.0版本,该版本支持mask rcnn和faster rcnn,低版本不支持哦,注意opencv4.0中在配置环境时,include下少了一个opencv文件夹,只有opencv2,这是正常的。
好了,废话不多说了,直接上源代码,该代码调用usb摄像头进行实时检测,基于单幅图像的检测修改下代码即可。
#include <fstream>
#include <sstream>
#include <iostream>
#include <string.h>#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>using namespace cv;
using namespace dnn;
using namespace std;// Initialize the parameters
float confThreshold = 0.5; // Confidence threshold
float maskThreshold = 0.3; // Mask thresholdvector<string> classes;
vector<Scalar> colors;// Draw the predicted bounding box
void drawBox(Mat& frame, int classId, float conf, Rect box, Mat& objectMask);// Postprocess the neural network's output for each frame
void postprocess(Mat& frame, const vector<Mat>& outs);int main()
{// Load names of classesstring classesFile = "./mask_rcnn_inception_v2_coco_2018_01_28/mscoco_labels.names";ifstream ifs(classesFile.c_str());string line;while (getline(ifs, line)) classes.push_back(line);// Load the colorsstring colorsFile = "./mask_rcnn_inception_v2_coco_2018_01_28/colors.txt";ifstream colorFptr(colorsFile.c_str());while (getline(colorFptr, line)) {char* pEnd;double r, g, b;r = strtod(line.c_str(), &pEnd);g = strtod(pEnd, NULL);b = strtod(pEnd, NULL);Scalar color = Scalar(r, g, b, 255.0);colors.push_back(Scalar(r, g, b, 255.0));}// Give the configuration and weight files for the modelString textGraph = "./mask_rcnn_inception_v2_coco_2018_01_28/mask_rcnn_inception_v2_coco_2018_01_28.pbtxt";String modelWeights = "./mask_rcnn_inception_v2_coco_2018_01_28/frozen_inference_graph.pb";// Load the networkNet net = readNetFromTensorflow(modelWeights, textGraph);net.setPreferableBackend(DNN_BACKEND_OPENCV);net.setPreferableTarget(DNN_TARGET_CPU);// Open a video file or an image file or a camera stream.string str, outputFile;VideoCapture cap(0);//根据摄像头端口id不同,修改下即可//VideoWriter video;Mat frame, blob;// Create a windowstatic const string kWinName = "Deep learning object detection in OpenCV";namedWindow(kWinName, WINDOW_NORMAL);// Process frames.while (waitKey(1) < 0){// get frame from the videocap >> frame;// Stop the program if reached end of videoif (frame.empty()) {cout << "Done processing !!!" << endl;cout << "Output file is stored as " << outputFile << endl;waitKey(3000);break;}// Create a 4D blob from a frame.blobFromImage(frame, blob, 1.0, Size(frame.cols, frame.rows), Scalar(), true, false);//blobFromImage(frame, blob);//Sets the input to the networknet.setInput(blob);// Runs the forward pass to get output from the output layersstd::vector<String> outNames(2);outNames[0] = "detection_out_final";outNames[1] = "detection_masks";vector<Mat> outs;net.forward(outs, outNames);// Extract the bounding box and mask for each of the detected objectspostprocess(frame, outs);// Put efficiency information. The function getPerfProfile returns the overall time for inference(t) and the timings for each of the layers(in layersTimes)vector<double> layersTimes;double freq = getTickFrequency() / 1000;double t = net.getPerfProfile(layersTimes) / freq;string label = format("Mask-RCNN on 2.5 GHz Intel Core i7 CPU, Inference time for a frame : %0.0f ms", t);putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));// Write the frame with the detection boxesMat detectedFrame;frame.convertTo(detectedFrame, CV_8U);imshow(kWinName, frame);}cap.release();return 0;
}// For each frame, extract the bounding box and mask for each detected object
void postprocess(Mat& frame, const vector<Mat>& outs)
{Mat outDetections = outs[0];Mat outMasks = outs[1];// Output size of masks is NxCxHxW where// N - number of detected boxes// C - number of classes (excluding background)// HxW - segmentation shapeconst int numDetections = outDetections.size[2];const int numClasses = outMasks.size[1];outDetections = outDetections.reshape(1, outDetections.total() / 7);for (int i = 0; i < numDetections; ++i){float score = outDetections.at<float>(i, 2);if (score > confThreshold){// Extract the bounding boxint classId = static_cast<int>(outDetections.at<float>(i, 1));int left = static_cast<int>(frame.cols * outDetections.at<float>(i, 3));int top = static_cast<int>(frame.rows * outDetections.at<float>(i, 4));int right = static_cast<int>(frame.cols * outDetections.at<float>(i, 5));int bottom = static_cast<int>(frame.rows * outDetections.at<float>(i, 6));left = max(0, min(left, frame.cols - 1));top = max(0, min(top, frame.rows - 1));right = max(0, min(right, frame.cols - 1));bottom = max(0, min(bottom, frame.rows - 1));Rect box = Rect(left, top, right - left + 1, bottom - top + 1);// Extract the mask for the objectMat objectMask(outMasks.size[2], outMasks.size[3], CV_32F, outMasks.ptr<float>(i, classId));// Draw bounding box, colorize and show the mask on the imagedrawBox(frame, classId, score, box, objectMask);}}
}// Draw the predicted bounding box, colorize and show the mask on the image
void drawBox(Mat& frame, int classId, float conf, Rect box, Mat& objectMask)
{//Draw a rectangle displaying the bounding boxrectangle(frame, Point(box.x, box.y), Point(box.x + box.width, box.y + box.height), Scalar(255, 178, 50), 3);//Get the label for the class name and its confidencestring label = format("%.2f", conf);if (!classes.empty()){CV_Assert(classId < (int)classes.size());label = classes[classId] + ":" + label;}//Display the label at the top of the bounding boxint baseLine;Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);box.y = max(box.y, labelSize.height);rectangle(frame, Point(box.x, box.y - round(1.5*labelSize.height)), Point(box.x + round(1.5*labelSize.width), box.y + baseLine), Scalar(255, 255, 255), FILLED);putText(frame, label, Point(box.x, box.y), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 0, 0), 1);Scalar color = colors[classId%colors.size()];// Resize the mask, threshold, color and apply it on the imageresize(objectMask, objectMask, Size(box.width, box.height));Mat mask = (objectMask > maskThreshold);Mat coloredRoi = (0.3 * color + 0.7 * frame(box));coloredRoi.convertTo(coloredRoi, CV_8UC3);// Draw the contours on the imagevector<Mat> contours;Mat hierarchy;mask.convertTo(mask, CV_8U);findContours(mask, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);drawContours(coloredRoi, contours, -1, color, 5, LINE_8, hierarchy, 100);coloredRoi.copyTo(frame(box), mask);}实验结果
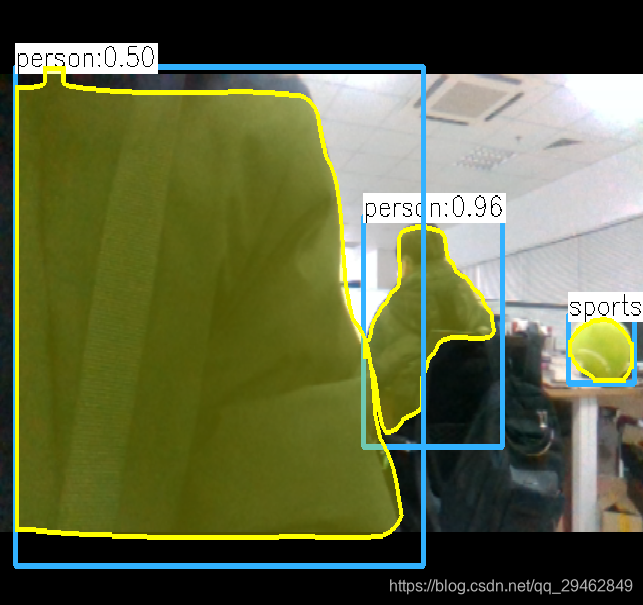

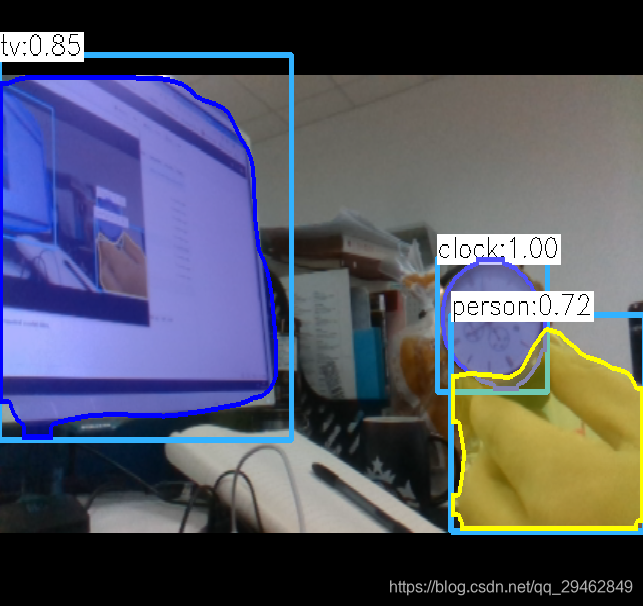
不过检测速度很慢,I7-8700k,GTX1060下需要1s每帧,达不到实时性要求。。。
实验数据
本博文所有的数据可以从这里下载:opencv调用mask rcnn数据
最后,欢迎加入3D视觉工坊,一起交流学习~
