机器学习:python常用可视化技巧
https://blog.csdn.net/Mr_tyting/article/details/73196119
我们在对数据进行预处理时,常常需要对数据做一些可视化的工作,以便能更清晰的认识数据内部的规律。
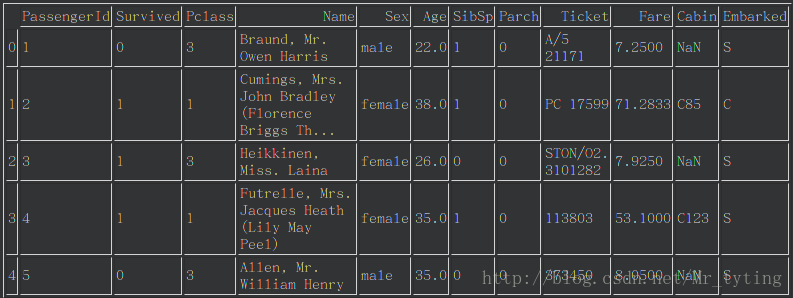
这里以kaggle案例泰坦尼克问题的数据做一些常用的可视化的工作。首先看下这个数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
sorted([f.name for f in matplotlib.font_manager.fontManager.ttflist])
data_train=pd.read_csv('train.csv')
plt.plot(data_train.Age)- 1
- 2
- 3
- 4
- 5
- 6
- 7
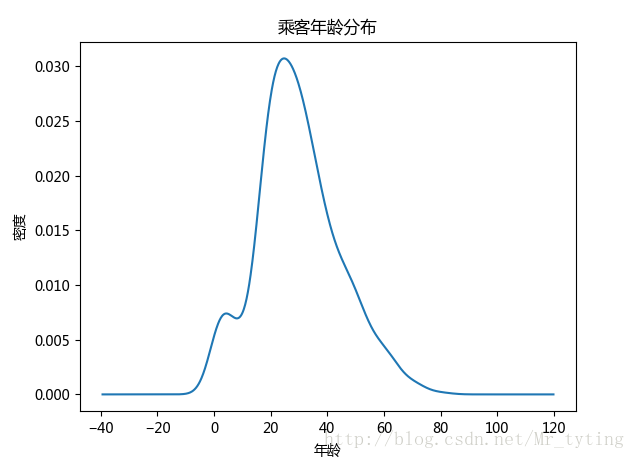
##现在我们想看看乘客年龄分布,kde就是密度分布,类似于直方图,数据落在在每个bin内的频率大小或者是密度大小
data_train.Age.plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"乘客年龄分布")- 1
- 2
- 3
- 4
- 5
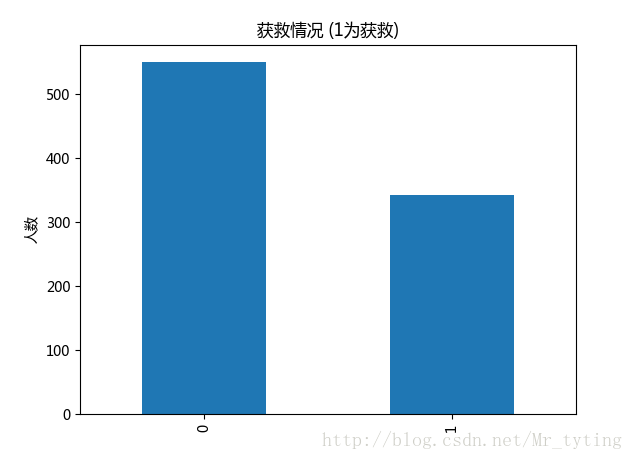
##现在看看获救人数和未获救人数对比
#plt.subplot2grid((2,3),(0,0))
data_train.Survived.value_counts().plot(kind='bar')# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")- 1
- 2
- 3
- 4
- 5
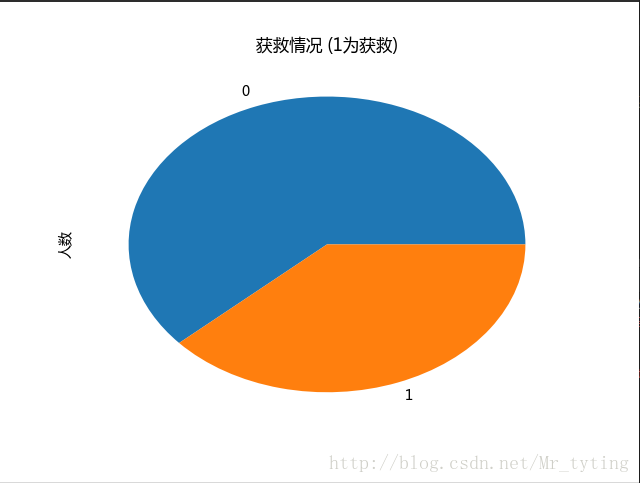
##也可以以饼状图看看获救人数和未获救人数对比
#plt.subplot2grid((2,3),(0,0))
data_train.Survived.value_counts().plot(kind='pie')# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")- 1
- 2
- 3
- 4
- 5
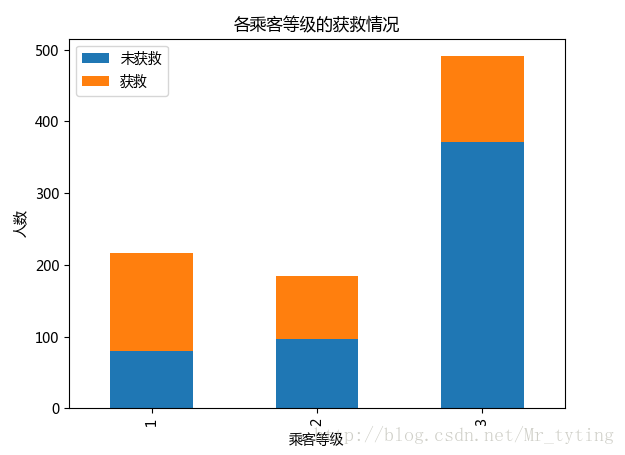
## 常看各乘客等级的获救情况
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
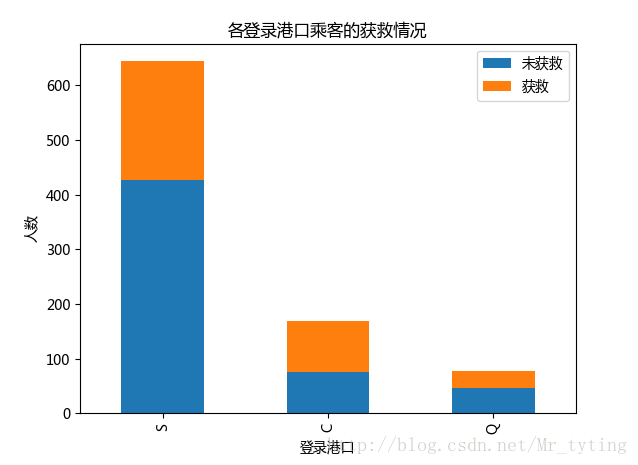
##查看各登录港口获救情况
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数") - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
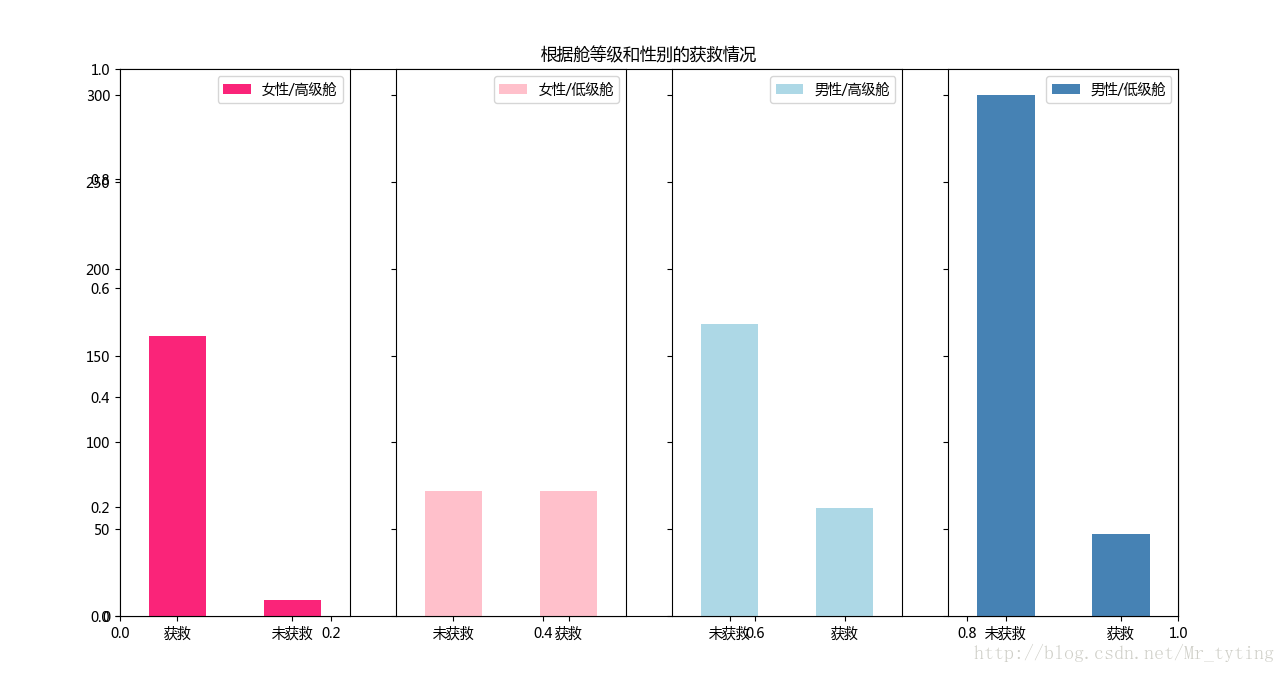
##再来看看各种级别舱情况下性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
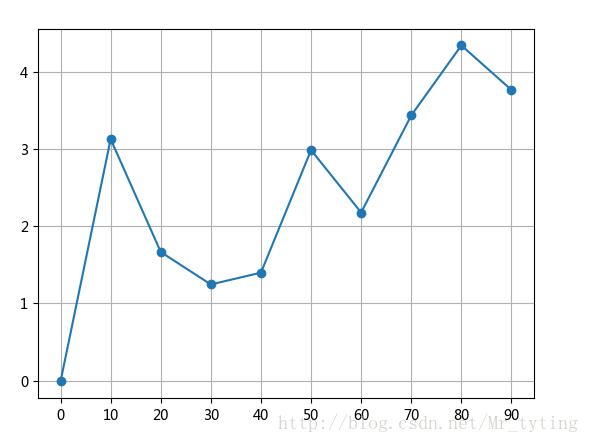
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltfig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(np.arange(0,100,10),np.random.randn(10).cumsum(),marker='o')
ax.set_xticks([0,10,20,30,40,50,60,70,80,90]) ##设置x轴上显示的刻度
ax.grid()## 显示方格
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
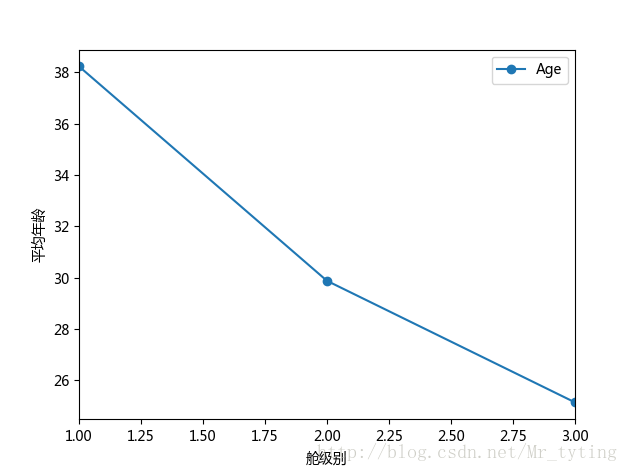
##现在我们想看看每个等级的舱的乘客的平均年龄
data_train.groupby('Pclass').mean().plot(y='Age',marker='o')
##注意参数marker='o'强调实际的数据点,会在实际的数据点上加一个实心点。如果要显示方格可在plot里面设置参数grid=True
plt.xlabel(u"舱级别")
plt.ylabel(u"平均年龄")- 1
- 2
- 3
- 4
- 5
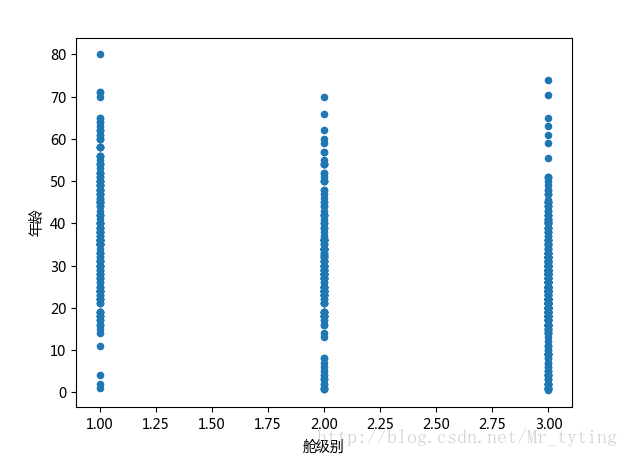
##也可以这样看看年龄和所在舱级别的关系
data_train.plot(x='Pclass',y='Age',kind='scatter')
plt.xlabel(u"舱级别")
plt.ylabel(u"年龄")
plt.show()- 1
- 2
- 3
- 4
- 5
我们换一个连续性变量多的数据集,看看特征直接相关度。
corr = df_train_origin[[‘temp’,’weather’,’windspeed’,’day’, ‘month’, ‘hour’,’count’]].corr()- 1
- 2
- 3
- 4
- 5
- 6
下面我们看看高维数据如何做可视化分析,首先咱们造个高维数据集
#numpy科学计算工具箱
import numpy as np
#使用make_classification构造1000个样本,每个样本有20个feature
from sklearn.datasets import make_classification
X, y = make_classification(1000, n_features=20, n_informative=2, n_redundant=2, n_classes=2, random_state=0)
#存为dataframe格式
from pandas import DataFrame
df = DataFrame(np.hstack((X, y[:, None])),columns = range(20) + ["class"])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
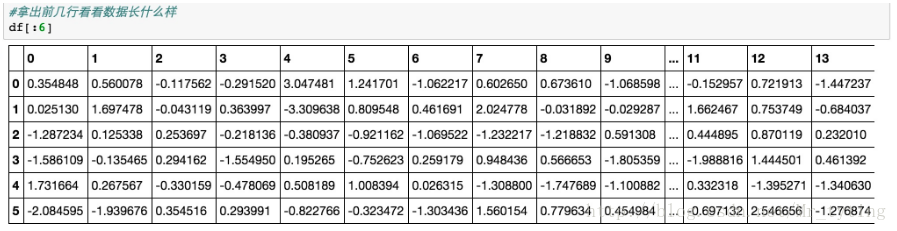
数据的可视化有很多工具包可以用,比如下面我们用来做数据可视化的工具包Seaborn。最简单的可视化就是数据散列分布图和柱状图,这个可以用Seanborn的pairplot来完成。以下图中2种颜色表示2种不同的类,因为20维的可视化没有办法在平面表示,我们取出了一部分维度,两两组成pair看数据在这2个维度平面上的分布状况,代码和结果如下:
#存为dataframe格式
from pandas import DataFrame
df = DataFrame(np.hstack((X, y[:, None])),columns = range(20) + ["class"])
import seaborn as sns
#使用pairplot去看不同特征维度pair下数据的空间分布状况
## vars表示把里面的特征两两做个可视化
_ = sns.pairplot(df[:50], vars=[8, 11, 12, 14, 19], hue="class", size=1.5)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
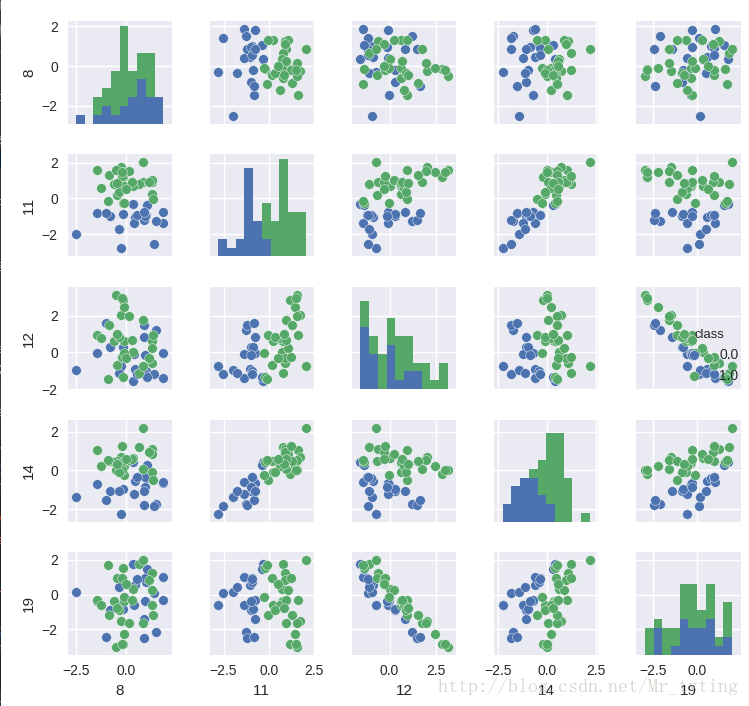
我们从散列图和柱状图上可以看出,确实有些维度的特征相对其他维度,有更好的区分度,比如第11维和14维看起来很有区分度。这两个维度上看,数据点是近似线性可分的。而12维和19维似乎呈现出了很高的负相关性。接下来我们用Seanborn中的corrplot来计算计算各维度特征之间(以及最后的类别)的相关性。代码和结果图如下:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 10))
_ = sns.linearmodels.corrplot(df, annot=False)
plt.show()- 1
- 2
- 3
- 4
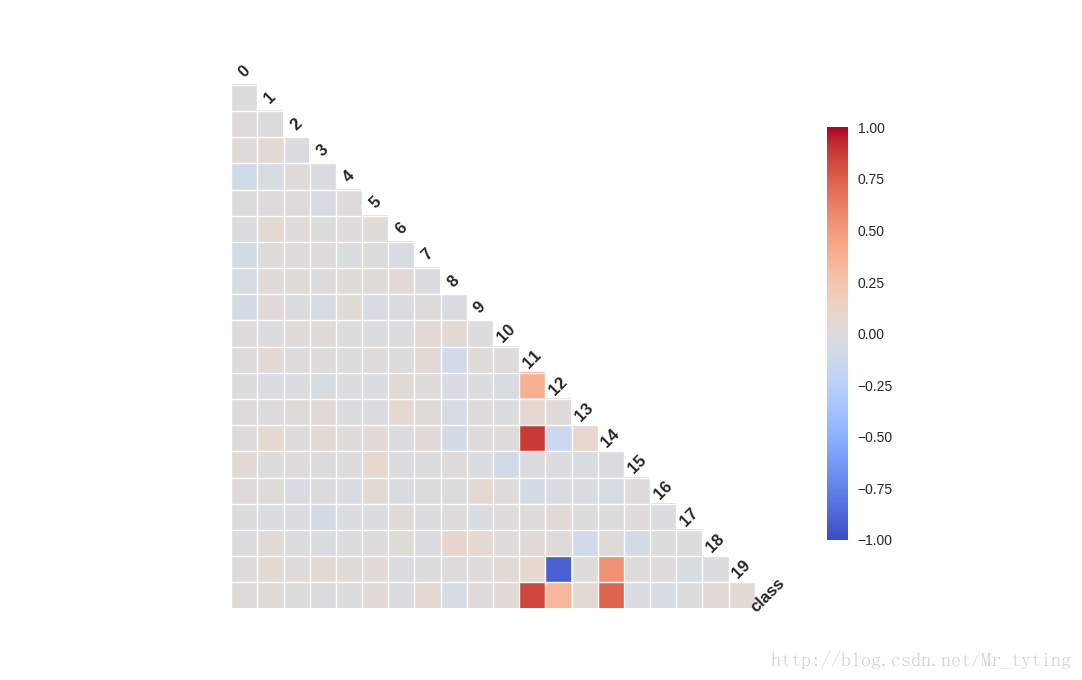
相关性图很好地印证了我们之前的想法,可以看到第11维特征和第14维特征和类别有极强的相关性,同时它们俩之间也有极高的相关性。而第12维特征和第19维特征却呈现出极强的负相关性。强相关的特征其实包含了一些冗余的特征,而除掉上图中颜色较深的特征,其余特征包含的信息量就没有这么大了,它们和最后的类别相关度不高,甚至各自之间也没什么先惯性。
新增部分
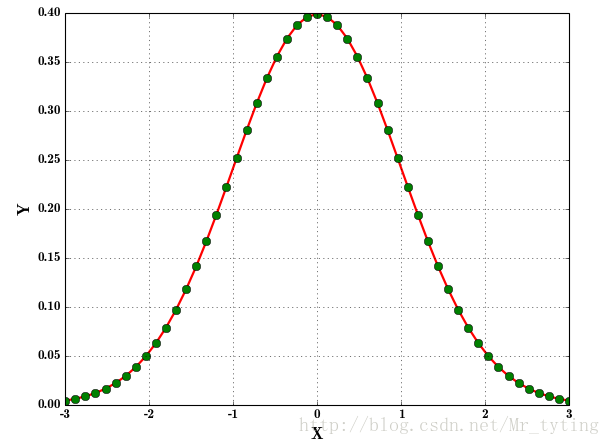
绘制正态分布概率密度函数代码如下
mu = 0##均值为0sigma = 1##方差为1x = np.linspace(mu - 3 * sigma, mu + 3 * sigma, 51)y = np.exp(-(x - mu) ** 2 / (2 * sigma ** 2)) / (math.sqrt(2 * math.pi) * sigma)print x.shapeprint 'x = \n', xprint y.shapeprint 'y = \n', y# plt.plot(x, y, 'ro-', linewidth=2)plt.figure(facecolor='w') ## 背景颜色取白色## 'r-':表示实线绘制,然后再画x,y,'go'表示用圆圈绘制,linewidth=2表示实线宽度2,markersize=8表示圆圈大小为8plt.plot(x, y, 'r-', x, y, 'go', linewidth=2, markersize=8)plt.xlabel('X', fontsize=15)##横轴用X标记plt.ylabel('Y', fontsize=15)##plt.title(u'高斯分布函数', fontsize=18)plt.grid(True)##画出虚线方格plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
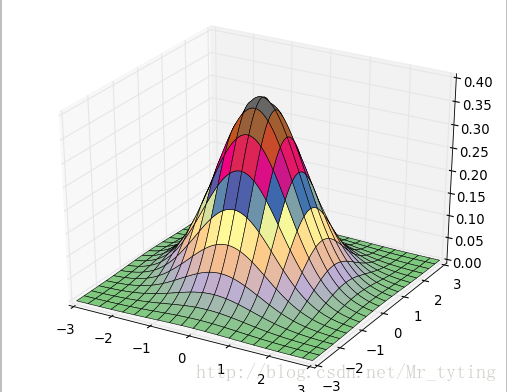
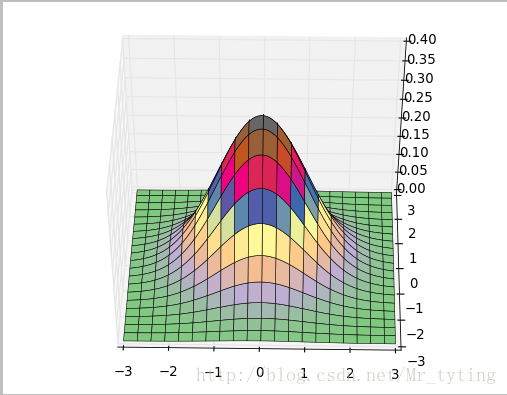
我们可以绘制在三维空间的正态分布图代码如下
#!/usr/bin/python
# -*- coding:utf-8 -*-import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import matplotlib.pyplot as plt
import mathx, y = np.mgrid[-3:3:100j, -3:3:100j]## 横轴,纵轴都在[-3,3)内取一百个点
# u = np.linspace(-3, 3, 101)
# x, y = np.meshgrid(u, u)## 这两行的效果同上面一行代码效果相同
z = np.exp(-(x**2 + y**2)/2) / math.sqrt(2*math.pi)## 三维正太分布
# z = x*y*np.exp(-(x**2 + y**2)/2) / math.sqrt(2*math.pi)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(x, y, z, rstride=5, cstride=5, cmap=cm.coolwarm, linewidth=0.1)
#ax.plot_surface(x, y, z, rstride=3, cstride=3, cmap=cm.Accent, linewidth=0.5) ## 参数rstride,cstride表示每几个取一个点,越小越密集
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
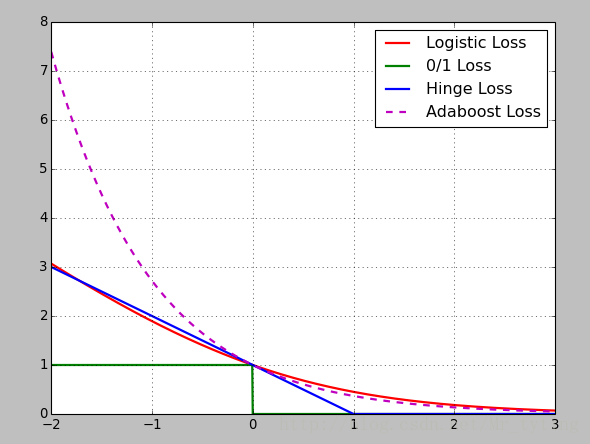
损失函数:Logistic损失(-1,1)/SVM Hinge损失/ 0/1损失
x = np.array(np.linspace(start=-2, stop=3, num=1001, dtype=np.float))y_logit = np.log(1 + np.exp(-x)) / math.log(2)y_boost = np.exp(-x)y_01 = x < 0y_hinge = 1.0 - xy_hinge[y_hinge < 0] = 0plt.figsize(figsize=(5,7),facecolor='w')##设置大小和背景颜色## 我们下面绘制的四幅图都是用的上面同一个plt,故下面四条线都在一张图中显示,如果想在不同图中显示,只需要在plt.plot之前重新定义一个figsize即可。plt.plot(x, y_logit, 'r-', label='Logistic Loss', linewidth=2)plt.plot(x, y_01, 'g-', label='0/1 Loss', linewidth=2)plt.plot(x, y_hinge, 'b-', label='Hinge Loss', linewidth=2)plt.plot(x, y_boost, 'm--', label='Adaboost Loss', linewidth=2) ## 'm--',1其中m表示颜色,--表示虚线,label表示图例中这条线的名称,linewidth线的宽度plt.grid()plt.legend(loc='upper right') ## 图例的位置# plt.savefig('1.png')plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
画散点图:
# -*- coding:utf-8 -*-import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeaturesdef extend(a, b):return 1.05*a-0.05*b, 1.05*b-0.05*aif __name__ == '__main__':pd.set_option('display.width', 200)data = pd.read_csv('iris.data', header=None)columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'type']data.rename(columns=dict(zip(np.arange(5), columns)), inplace=True)data['type'] = pd.Categorical(data['type']).codesprint data.head(5)x = data.loc[:, columns[:-1]]y = data['type']pca = PCA(n_components=2, whiten=True, random_state=0)x = pca.fit_transform(x)print '各方向方差:', pca.explained_variance_print '方差所占比例:', pca.explained_variance_ratio_print x[:5]cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])mpl.rcParams['font.sans-serif'] = u'SimHei'mpl.rcParams['axes.unicode_minus'] = Falseplt.figure(facecolor='w')plt.scatter(x[:, 0], x[:, 1], s=30, c=y, marker='o', cmap=cm_dark)#s表示散点圆圈缩放大小,c表示类别,marker表示标记为圆圈,cmp表示不同类的对比颜色plt.grid(b=True, ls=':')plt.xlabel(u'组份1', fontsize=14)plt.ylabel(u'组份2', fontsize=14)plt.title(u'鸢尾花数据PCA降维', fontsize=18)# plt.savefig('1.png')plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
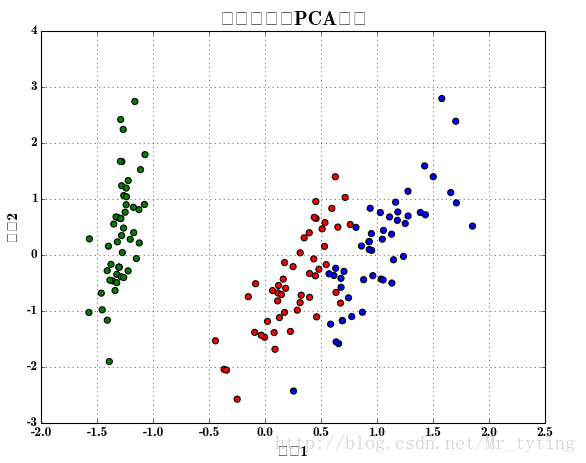
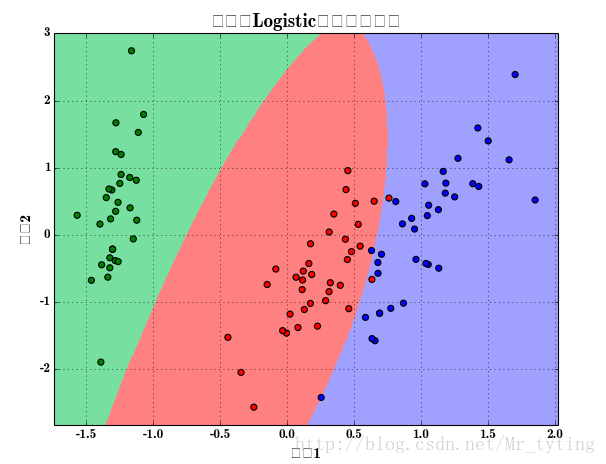
接着上面画出逻辑回归的分类效果图:
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7)model = Pipeline([('poly', PolynomialFeatures(degree=2, include_bias=True)),('lr', LogisticRegressionCV(Cs=np.logspace(-3, 4, 8), cv=5, fit_intercept=False))])model.fit(x, y)print '最优参数:', model.get_params('lr')['lr'].C_y_hat = model.predict(x)print '训练集精确度:', metrics.accuracy_score(y, y_hat)y_test_hat = model.predict(x_test)print '测试集精确度:', metrics.accuracy_score(y_test, y_test_hat)N, M = 500, 500 # 横纵各采样多少个值x1_min, x1_max = extend(x[:, 0].min(), x[:, 0].max()) # 第0列的范围x2_min, x2_max = extend(x[:, 1].min(), x[:, 1].max()) # 第1列的范围t1 = np.linspace(x1_min, x1_max, N)t2 = np.linspace(x2_min, x2_max, M)x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点x_show = np.stack((x1.flat, x2.flat), axis=1) # 测试点y_hat = model.predict(x_show) # 预测值y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同plt.figure(facecolor='w')plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示plt.scatter(x[:, 0], x[:, 1], s=30, c=y, edgecolors='k', cmap=cm_dark) # 样本的显示plt.xlabel(u'组份1', fontsize=14)plt.ylabel(u'组份2', fontsize=14)plt.xlim(x1_min, x1_max)plt.ylim(x2_min, x2_max)plt.grid(b=True, ls=':')## 不同类的区域显示不同的颜色patchs = [mpatches.Patch(color='#77E0A0', label='Iris-setosa'),mpatches.Patch(color='#FF8080', label='Iris-versicolor'),mpatches.Patch(color='#A0A0FF', label='Iris-virginica')]plt.legend(handles=patchs, fancybox=True, framealpha=0.8, loc='lower right')plt.title(u'鸢尾花Logistic回归分类效果', fontsize=17)plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
利用matplot.pyplot.plot画出某个特征或者某些特征与对应的类别标签的关系
plt.figure(facecolor='w')plt.plot(data['TV'], y, 'ro', label='TV')plt.plot(data['Radio'], y, 'g^', label='Radio')plt.plot(data['Newspaper'], y, 'mv', label='Newspaer')plt.legend(loc='lower right')plt.xlabel(u'广告花费', fontsize=16)plt.ylabel(u'销售额', fontsize=16)plt.title(u'广告花费与销售额对比数据', fontsize=20)plt.grid()plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
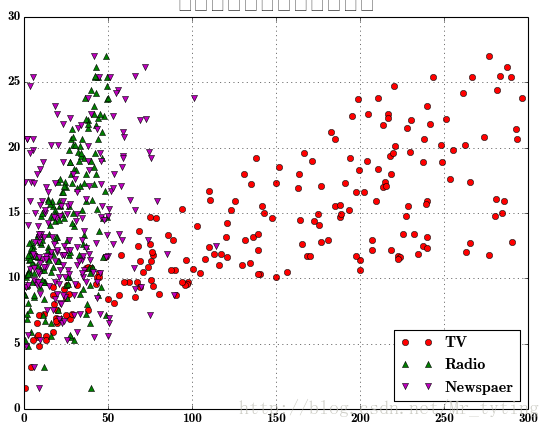
这里总结下plot函数里面的形状参数:’ro’:表示红色圆圈,’g^’:蓝色上三角,前一个字母表示颜色,后一个字符表示形状。可用的形状有’^’,’V’,’‘,’>’,’<’,’:’,’-‘,’–’等。*
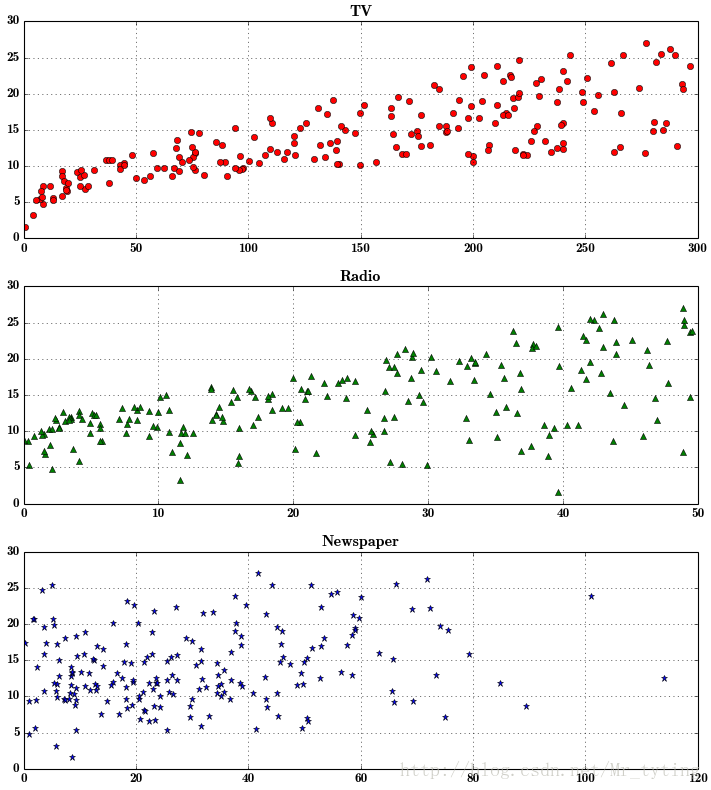
把上面三个图分开来画,凸显每个特征与类别的关系
plt.figure(facecolor='w', figsize=(9, 10))plt.subplot(311) ##这个plt画出的图,分有3个位置,3行1列,占第一个位置plt.plot(data['TV'], y, 'ro') plt.title('TV')plt.grid()plt.subplot(312)##占第二个位置plt.plot(data['Radio'], y, 'g^')plt.title('Radio')plt.grid()plt.subplot(313)## 占第三个位置plt.plot(data['Newspaper'], y, 'b*')plt.title('Newspaper')plt.grid()plt.tight_layout()plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15