Unix/Linux编程:四种mbuf
网络协议对内核的存储器管理能力提出了很多要求。这些要求包括能方便的可变长缓存,能在缓存头部和尾部添加数据(封装时需要添加首部),能从缓存中移除数据(解封装时要移除首部),并能尽量减少为这些操作所做的数据复制。内核中的存储器管理调度直接关系到联网协议的性能
在伯克利联网代码设计中的一个基本概念就是存储器缓存,称作一个 mbuf(“memory buffer”),在整个联网代码中用于存储各种信息。
mbuf的主要用途就是保存在进程和网络接口间相互传递的用户数据,但mbuf也用于保存其他各种数据:源与目标地址、插口选项等等
下图显示了我们要遇到的4种不同类型的mbuf,它们依据在成员m_flags中填写的不同标志M_PKTHDR和M_EXT而不同:
- mbuf结构的大小总是128字节
- 既然有些协议(例如UDP )允许零长记录,当然就可以有 m_len为0的数据缓存。
- 带有簇的mbuf总是包含缓存的起始地址(m_ext.ext_buf)和它的大小(m_ext.ext_size)。

- 如果m_flags等于0,mbuf只包含数据。(上图中,结构m_hdr中有六个成员,它的总长是 20字节。当我们查看此结构的 C语言定义时,会看见前四个成员每个占用 4字节而后两个成员每个占用 2字节。这里我们没有区分4字节成员和2字节成员。)
- 在mbuf中有108字节的数据空间(m_dat数组),指针m_data指向这108字节缓存中的某个位置。我们所示的m_data指向缓存的起始,但它能指向缓存的任意位置。
- 成员m_len指示了从m_data开始的数据字节数。下图是是这类mbuf的一个例子

- 如上图,第二类mbuf的m_flags值是M_PKTHDR,它指示这是一个分组首部,描述一个分组数据的第一个mbuf。数据仍然保存在这个mbuf中,但是由于分组首部占用了 8字节,只有100字节的数据可存储在这个 mbuf中(在m _ p k t d a t数组中)。下图是这种mbuf的一个例子
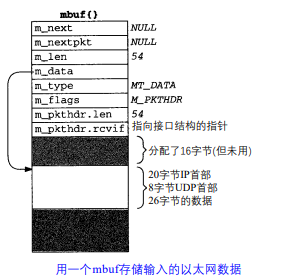
- 这个mbuf是一个分组首部(m_flags被设置M_PKTHDR),它是一个数据记录的第一个mbuf。
- 分组首部的成员m_len包含数据的总长度(这里表示以太网接收了54字节的数据并复制到一个mbuf中:20字节IP首部、8字节UDP首部及26字节数据()
- 成员rcvif包含一个指针,它指向接收数据的接口的接口结构
- mbuf的前16字节数据空间被分配到一个接口层首部,但没有使用。数据就存储在这个mbuf中,64字节的数据存储在剩余84字节的空间中
- 第三种mbuf不包含分组首部(没有设置M_PKTHDR),但包含超过208字节的数据,这时用到一个叫做"簇"的外部缓存(设置M_EXT)。
- 在此mbuf仍然为分组首部结构分配了空间,但没有用------如下图,我们用阴影显示出来。
- Net/3分配一个大小为1024或2048的簇。而不是使用多个mbuf来保存数据。
- 在这个mbuf中,指针m_data指向这个簇中的某个位置
- mbuf的标志是M_EXT,它表示“外部的”缓存。
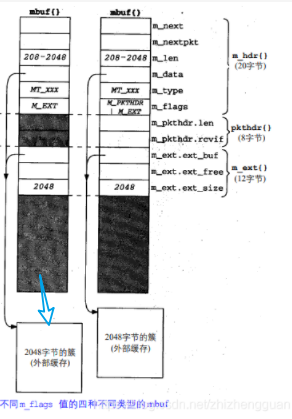
- 最后一种mbuf包含一个分组首部,并包含超过208字节的数据。同时设置了标志M_PKTHDR和M_EXT。
关于mbuf的其他其他:
- 指针m_next把mbuf链接在一起,把一个分组形成一条mbuf链表。如下图所示
- 指针m_nextpkt把多个分组链接成一个mbuf链表队列。在队列中的每个分组可以是一个单独的mbuf,也可以是一个mbuf链表。每个分组的第一个 mbuf包含一个分组首部。
如下图所示,在一个队列中有两个分组。
- 我们所示的队列有一个头指针和一个尾指针。这就是Net/3处理接口输出队列的方法。
- 带有UDP数据报分组首部的第一个 mbuf的类型是MT_DATA,但带有TCP报文段分组首部的第一个mbuf的类型是MT_HEADER。这是由于UDP和TCP采用了不同的方式往数据中添加首部造成的,但没有什么不同。这两种类型的mbuf本质上一样。链表中第一个mbuf的m_flags的值M_PKTHDR指示了它是一个分组首部。
- TCP段包含1460字节的用户数据。
- TCP数据包含在一个簇中,并且有一个mbuf包含了它的以太网、 IP与TCP首部。通过这个簇,我们可以看到指向簇的数据指针 (m_data)不需要指向簇的起始位置

代码介绍
mbuf函数在一个单独的C文件中,并且mbuf宏与各种mbuf定义都在一个单独的头文件中,如下表所示。
| 文 件 | 说 明 |
|---|---|
| 4.4BSD-Lite\usr\src\sys\sys\mbuf.h | mbuf结构、mbuf宏与定义 |
| 4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c | mbuf函数 |
mbuf.h
全局变量mbstat
在全局结构mbstat 中维护各种统计信息
/** Mbuf statistics.*/
struct mbstat {u_long m_mbufs; /* 从页池获得的(未用)mbuf */u_long m_clusters; /* 从页池中获取的簇 */u_long m_spare; /* 备用字段 */u_long m_clfree; /* 自由簇 */u_long m_drops; /* 分配(未用)空间失败的次数 */u_long m_wait; /* 等待(未用)空间的次数 */u_long m_drain; /*调用协议的drain函数来回收空间的次数 */u_short m_mtypes[256]; /*类型特定的 mbuf 分配 */
};
mbuf统计显示了在Net/3源代码中的一种通用技术。内核在一个全局变量(这里是结果mstat)中保持对某些统计信息的跟踪。当内核在运行时,一个进程可以检测这些统计。
mbuf定义
#define MSIZE 128 // (sizeof(struct mbuf)) 每个mbuf的大小 --- 128 字节
#define MLEN (MSIZE - sizeof(struct m_hdr)) /* normal data len -- 在正常mbuf中的最大数据量 -- 108字节*/
#define MHLEN (MLEN - sizeof(struct pkthdr)) /* data len w/pkthdr --- 带分组首部的mbuf的最大数据量 --- 100字节*//* header at beginning of each mbuf: */
struct m_hdr {struct mbuf *mh_next; /* next buffer in chain */struct mbuf *mh_nextpkt; /* next chain in queue/record */int mh_len; /* amount of data in this mbuf */caddr_t mh_data; /* location of data */short mh_type; /* type of data in this mbuf */short mh_flags; /* flags; see below */
};/* record/packet header in first mbuf of chain; valid if M_PKTHDR set */
struct pkthdr {int len; /* total packet length */struct ifnet *rcvif; /* rcv interface */
};/* description of external storage mapped into mbuf, valid if M_EXT set */
struct m_ext {caddr_t ext_buf; /* start of buffer */void (*ext_free)(); /* free routine if not the usual */u_int ext_size; /* size of buffer, for ext_free */
};struct mbuf {struct m_hdr m_hdr;union {struct {struct pkthdr MH_pkthdr; /* M_PKTHDR set */union {struct m_ext MH_ext; /* M_EXT set */char MH_databuf[MHLEN];} MH_dat;} MH;char M_databuf[MLEN]; /* !M_PKTHDR, !M_EXT */} M_dat;
};// 下面的这11个#define语句简化了对mbuf 结构中的结构与联合的成员的访问
#define m_next m_hdr.mh_next // m_next把mbuf链接成一个mbuf链表
#define m_len m_hdr.mh_len
#define m_data m_hdr.mh_data
#define m_type m_hdr.mh_type
#define m_flags m_hdr.mh_flags
#define m_nextpkt m_hdr.mh_nextpkt // 指针m_nextpkt把mbuf链表链接成一个mbuf队列
#define m_act m_nextpkt
#define m_pkthdr M_dat.MH.MH_pkthdr
#define m_ext M_dat.MH.MH_dat.MH_ext
#define m_pktdat M_dat.MH.MH_dat.MH_databuf
#define m_dat M_dat.M_databuf
- 结构mbuf 是用一个m_hdr 结构跟着一个联合来定义的。如注释所示,联合的内容依赖于标志
M_PKTHDR和M_EXT - 最下面的这11个#define 语句简化了对mbuf 结构中的结构与联合的成员的访问。我们会看到这种技术普遍应用于Net/3源代码中,只要是一个结构包含其他结构或联合这种情况。
- m_next把mbuf链接成一个mbuf链表, 指针m_nextpkt把mbuf链表链接成一个mbuf队列
- 下图所示的是成员m_flags的五个独立的值
- 我们已经说明了标志 M_EXT 和M_PKTHDR 。
- M_EOR在一个包含记录尾的mbuf中设置。Internet协议(例如TCP)从来不设置这个标志,因为TCP提供一个无记录边界的字节流服务。但OSI和XNS运输层需要用到这个标识。在插口层我们会遇到这个标识,因为这一层是协议无关的,并且它要处理来自或者发往所有运输层的数据
- 当要往一个链路层广播地址会在多播地址发送分组,或者要从一个链路层广播地址会在多播地址接收一个分组时,在这个mbuf中要设置接下来的两个标志:M_BCAST 和M_MCAST 。这两个常量是协议层与接口层之间的标志(如图1.3)
- 对于最后一个标志值M_COPYFLAGS ,当一个mbuf包含一个分组首部的副本时,这个标志表明这些标志是复制的。
| m_flags | 说 明 |
|---|---|
| M_BCAST (bcast) | 作为链路层广播发送/接收 |
| M_EOR | 记录结束 |
| M_EXT | 此mbuf带有簇(外部缓存) |
| M_MCAST | 作为链路层多播发送/接收 |
| M_PKTHDR | 形成一个分组(记录)的第一个mbuf |
| M_COPYFLAGS | M_PKTHDR/M_EOR/M_BCAST/M_MCAST |

- 图2.10所示的常量MT_xxx用于成员m_type,指示存储在mbuf中的数据的类型。虽然我们总认为一个mbuf是用来存放要发送或者接收的用户数据,但mbuf可以存储各种不同的数据结构。比如图1.6中的一个mbuf被用来存放一个插口地址,其中的目标地址用于系统调用sendto。它的m_type成员被设置为MT_SONAME


- 不是图2-10中所有的mbuf类型值都用于Net/3。有些已不再使用(MT_HTABLE),还有一些不用于TCP/IP代码中,但用于内核的其他地方。例如, MT_OOBDATA用于OSI和XNS协议,
但是T C P用不同方法来处理带外 ( out-of-band )数据
简单的mbuf宏和函数
有超过两打的宏和函数来处理mbuf(分配一个mbuf,释放一个mbuf,等等)。让我们来查看几个宏与函数的源代码,看看它们是如何实现的。
有些操作既提供了宏也提供了函数。宏版本的名称是以 M开头的大写字母名称,而函数是以m _开始的小写字母名称。两者的区别是一种典型的时间 -空间互换。宏版本在每个被用到的地方都被C预处理器展开(要求更多的代码空间 ),但是它在执行时更快,因为它不需要执行函数调用(对于有些体系结构,这是费时的 )。而对于函数版本,它在每个被调用的地方变成了一些指令(参数压栈,调用函数等),要求较少的代码空间,但会花费更多的执行时间。
m_get
让我们先看一下m_get。这个函数仅仅就是宏MGET的展开,功能是分配一个mubuf
//4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c
struct mbuf * m_get(int nowait, int type) {struct mbuf *m;MGET(m, nowait, type);return (m);
}
这个调用表明参数nowait的值为M_WAIT或者M_DONTWAIT ,它取决于存储器不可用时是否要求等待。比如,当插口层请求分配一个mbuf来存储sendto系统调用的目的地址是,它指定M_WAIT,因此在此阻塞是没有问题的。但是当以太网设备驱动程序请求分配一个mbuf来存储一个接收的帧时,它指定M_DONTWAIT,因为它是作为一个设备中断处理来执行的,不能进入睡眠状态来等待一个mbuf。在这种情况下,如果存储器不可用,设备驱动程序丢弃这个帧比较好
/* flags to m_get/MGET */
#define M_DONTWAIT M_NOWAIT
#define M_WAIT M_WAITOK
MEGT宏
// mbuf.h
#define MGET(m, how, type) { \MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \if (m) { \(m)->m_type = (type); \MBUFLOCK(mbstat.m_mtypes[type]++;) \(m)->m_next = (struct mbuf *)NULL; \(m)->m_nextpkt = (struct mbuf *)NULL; \(m)->m_data = (m)->m_dat; \(m)->m_flags = 0; \} else \(m) = m_retry((how), (type)); \
}
- 如下代码,MGET一开始调用内核宏MALLOC,它是通过内核存储器进行的。数组mbtypes把mbuf的MT_XXX值转换成相应的M_xxx值(图2-10)。若存储器被分配,成员m_type被上设置为参数中的值
#define MGET(m, how, type) { \MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \if (m) { \(m)->m_type = (type); \
- 如下代码,用于跟踪统计每种mbuf类型的内核结构加1(mbstat)。当执行这句时,宏MBUFLOCK把它作为参数来改变处理器优先级(图1-13),然后把优先级恢复为原值。这防止正在执行语句mbstat.m_mtypes[type]++;时被网络设备中断
MBUFLOCK(mbstat.m_mtypes[type]++;) \
- 网络代码处理输入分组使用的是异步和终端驱动方式。首先,一个设备终端引发接口层代码执行,然后它产生一个软终端引发协议层代码执行。当内核完成这些级别的中断后,指向插口代码
- 如下给每个硬件和软件中断分配一个优先级

-如下代码,两个mbuf指针,m_next 和m_nextpkt ,被设置为空指针。如有必要,由调用者把这个mbuf加入到一个链或者队列中
(m)->m_next = (struct mbuf *)NULL; \(m)->m_nextpkt = (struct mbuf *)NULL; \
- 最后(如下),数据指针被设置为指向108字节的mbuf缓存的起始,而标志被设置为0
(m)->m_data = (m)->m_dat; \(m)->m_flags = 0; \
- 如下代码,如果内核的存储器分配调用失败,调用m_type。
} else \(m) = m_retry((how), (type)); \
调用MGET来分配存储sendto系统调用的目标地址的mbuf如下所示(虽然指定了M_WAIT,但返回值仍然要检测,因为,如下m_retry函数所示,等待一个mbuf并不保证它是可用的):
MEGT(m, M_WAIT, MT_SONAME);
if(m == NULL){return (ENOBUFS);
}
m_retry函数
// //4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c
struct mbuf * m_retry(int i, t)
{struct mbuf *m;m_reclaim();
#define m_retry(i, t) (struct mbuf *)0MGET(m, i, t);
#undef m_retryreturn (m);
}
- 如下代码,被m_retry调用的第一个函数是m_reclaim。每个协议都能定义一个“drain”函数,在系统缺乏可用存储器时能被m_reclaim调用。当IP的drain函数被调用时,所有等待重新组成的IP数据报的IP分片被丢弃。TCP的drain函数什么都不做,而UDP甚至没有定义一个drain函数
// //4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c
struct mbuf * m_retry(int i, t)
{struct mbuf *m;m_reclaim();
- 如下代码,因为在调用了m_reclaim后有可能有机会得到更多的存储器,因此再次调用宏MGET,试图获得mbuf。在展开宏MEGT之前,m_retry会定义为一个空指针。这可以防止当存储器仍然不可用时的无休止的循环。在MEGT展开之后,这个m_retry的临时定义就被取消了,以防止再次之后由对MEGT的其他引用
#define m_retry(i, t) (struct mbuf *)0MGET(m, i, t);
#undef m_retry
m_devget和m_pullup函数
m_pullup用来保证指定数目的字节(相应协议首部的大小)在链表的第一个mbuf中紧挨着存放;即这些指定数目的字节被复制到一个新的mbuf并并紧接着存放。为了理解m_pullup的用法,必须查看它的实现及相关的函数 m_devget和宏mtod与dtom。在分析这些问题的同时我们还可以再次领会Net/3中mbuf的用法。
m_devget函数
当接收到一个以太网帧时,设备驱动程序调用函数m_devget来创建一个mbuf链表,并把设备中的帧复制到这个链表中。根据所接收帧的长度(不包括以太网首部),可能导致4中不同的mbuf链表。图2-14所示的是前两种

- 上图左边的mbuf用于数据长度在0-84字节之间的情况。在这个图中,我们假定有52字节的数据:一个20字节IP首部和一个32字节的TCP首部(标准的20字节的TCP首部加上12字节的TCP选项),但不包括TCP数据,
- 既然m_devget返回的mbuf数据从IP首部开始,m_len的实际最小值是28:20字节的IP首部+8字节的UDP首部+一个0字节的UDP数据报
- m_devget在这个mbuf的开始保留了16字节未用。
- 虽然14字节的以太网首部不存放在这里,但还是分配了一个14字节的用于输出的以太网首部,这是同一个mbuf,用于输出
- 我们会遇到两个函数:icmp_reflect和tcp_respond,它们通过把接收到的mbuf作为输出mbuf来产生一个应用。在这两种情况中,接收的数据报应该少于84字节,因此很容易在前面保留16字节的空间,这样在建立输出数据报时可以节省时间。
- 分配16字节而不是14字节的原因是为了在mbuf中用长字对准方式存储IP首部
- 如果数据报在84-100字节之间,就仍然存放在一个分组首部mbuf中,但在开始没有16字节的空间。数据存储在数组m_pktdat的开始,并且任何未用的空间放在这个数组的后面

-
图2-15所示的是m_devget创建的第3种mbuf。当数据在101-207字节之间时,要求有两个mbuf。前100字节存放在第一个mbuf中(有分组首部的mbuf),而剩下的存放在第二个mbuf中。
-
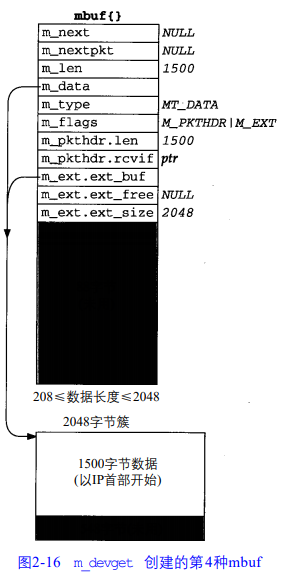
图2-16所示的是m_devget创建的第四种mbuf。如果数据超过或等于 208 字节(MINCLBYTES),要用一个或多个簇。

mtod和dtom宏
- mtod的功能是:将m指向的mbuf的数据区指针的类型转换成type类型
- dtom的功能是:将执行一个mbuf数据区中的某个位置的指针x转换成一个指向这个mbuf的起始的指针
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
/** Macros for type conversion* mtod(m,t) - 将mbuf指针转换为正确类型的数据指针* dtom(x) - 将mbuf中的数据指针转换为mbuf指针(XXX)*/
#define mtod(m,t) ((t)((m)->m_data))
#define dtom(x) ((struct mbuf *)((int)(x) & ~(MSIZE-1)))
// struct mbuf *dtom(void *x);
// type m t o d(struct mbuf *m, t y p e)
mtod(“mbuf到数据”)返回一个指向mbuf数据的指针,并把指针转换为指定类型。例如代码
struct mbuf *m;
struct ip *ip;ip = mtod(m, struct ip *);
ip->ip_v = IPVERSION;
宏dtom(“数据到mbuf”)取得一个存放在一个mbuf中任意位置的数据的指针,并返回这个mbuf结构本身的一个指针。比如,如果我们知道ip指向一个mbuf的数据区,下面的语句序列:
struct mbuf *m;
struct ip *ip;m = dtop(ip);
把指向这个mbuf开始的指针存放在m中。我们知道MSIZE(128)是2的幂,并且内核存储器分配器总是为mbuf分配连续的MSIZE字节的存储块,dtom仅仅是清除参数中指针的低位来发现这个mbuf的起始位置
宏dtom用一个问题:当它的参数指向一个簇,或者在一个簇内,如下图,它就不能正确使用了。因为那里没有指针从簇内值回mbuf结构,dtom不能被使用。这导致了下一个函数m_pullup
m_pullup函数和连续的协议首部
函数m_pullup有两个目的。第一个是当一个协议(IP/ICMP/IGMP/UDP/TDP)发现第一个m_buf的数据量(m_len)小于协议首部的最小长度(IP是20、UDP是8、TCP是20)时,调用m_pullup是基于假定协议首部的剩余部分存放在链表的下一个mbuf。m_pullup重新安排mbuf链表,使得前N字节的数据被连续的存放在链表的第一个mbuf中。N是这个函数的第一个参数,它必须小于等于100(MHLEN)。如果前N字节连续存放在第一个mbuf中,则可以使用宏mtod和dtom
例如,我们在IP输入例程中遇到下面这样的代码:
if(m->m_len < sizeof(struct ip) && (m = m_pullup(m, sizeof(struct ip)) == 0)){ipstat.ips_toosmall++;goto next;
}ip = mtod(m, struct ip *);
如果第一个mbuf中的数据小于20(标准IP首部的大小),m_pullup被调用。函数m_pullup有两个原因会失败:
- 如果它需要其他mbuf并且调用MGET失败
- 如果整个mbuf链表中的数据总数小于要求的连续字节数(即上面收到的N,本例中是20)
通常,失败是因为第二个原因。在本例中,如果mbuf失败(mbuf链表中的数据小于20字节),一个IP计数器加1,并且此IP数据报被丢弃。
实际上,在这种情况下,m_pullup很少能被调用,并且当它被调用时,通常会失败
大多数 m_pullup的失败是因为接收的I P数据报太小。
m_pullup和IP的分片与重组
使用m_pullup的第二个用途涉及到IP和TCP的重组。假定IP接收到一个长度为296的分组。这个分组时一个大的数据报的一个分片。这个从设备驱动程序传到IP输入的mbuf看起来像是图2-16中的一个mbuf:296字节的数据放在一个簇中。具体如下2-27图

问题在于,IP的分片算法将各分片都存放在一个双向链表中,使用IP首部中的源于目标IP地址来存放地址来存放向前与向后链表指针。但是如果这个IP首部在一个簇中,如上图2-17所示,这些链表指针会存放在这个簇中,并且当以后遍历链表时,指向IP首部的指针(即指向这个簇的起始的指针 )不能被转换成指向 mbuf的指针,即不能使用宏dtom
为解决这个问题,当接收到一个分片时,如果分片存放在一个簇中,IP分片例程总是调用m_pullup。它强行将20字节的IP首部放在它自己的mbuf中,代码如下:
if(m->m_flags & M_EXT){if((m = m_pullup(m, sizeof(struct ip))) == 0){ipstat.ips_toosmall++;goto next;
}ip = mtod(m, struct ip *);
}
下图所示是调用了m_pullup后得到的mbuf链表。m_pullup分配了一个新的mbuf,挂载链表的前面,并从簇中取走了40字节放入到这个新mbuf中。之所以取40字节而不是仅要求的20字节,是为了保证以后在IP把数据报传给一个高层协议(比如ICMP、IGMP、UPD、TCP)时,高层协议能挣钱处理。采用40是因为最大协议首部通常是一个20字节的IP首部和20字节的TCP首部的组合
下图中,IP分片算法在左边的mbuf包保存了一个指向IP首部的指针,并且可以使用dtom将这个指针转换成一个指向mbuf本身的指针

TCP重组避免使用m_pullup
重组TCP报文使用了一个不同的技术而不是调用m_pullup。这是因为m_pullup开销较大:分配存储器并且数据从一个簇复制到一个mbuf中。TCP试图尽可能的避免数据的复制
m_pullup使用总结
我们已经讨论了关于使用m_pullup的三种情况‘
- 大多数设备驱动程序不把一个IP数据报的第一部分分隔到几个mbuf中。假设协议首部都紧挨着存放,则每个协议中调用m_pullup的可能性很小。如果调用m_pullup,通常是因为IP数据报太小,并且m_pullup返回一个差错,这时数据报被丢弃,并且差错计数器+1
- 对于每个接收到的IP分片,当IP数据报被存放在一个簇中时,m_pullup被调用。这意味着,几乎对于每个接收的分配都要调用m_pullup,因为大多数分配的长度大于208字节
- 只要TCP报文段不被IP分片,接收一个TCP报文段,不论是否失序,都不需要调用m_pullup。这是避免IP对TCP分片的一个原因
其他mbuf函数
MCLGET
获得一个簇(一个外部缓存)并将m指向的数据指针(m_data)设置为指向一个簇。如果存储器不可用,返回时不设置mbuf的M_EXT标志
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
//void MCLGET(struct mbuf * m, int nowait);
#define MCLGET(m, how) \{ MCLALLOC((m)->m_ext.ext_buf, (how)); \if ((m)->m_ext.ext_buf != NULL) { \(m)->m_data = (m)->m_ext.ext_buf; \(m)->m_flags |= M_EXT; \(m)->m_ext.ext_size = MCLBYTES; \} \}MFREE
释放一个m指向的mbuf。若m指向一个簇(设置了M_EXT),这个簇的引用计数器减 1,但这个簇并不被释放,直到它的引用计数器降为 0
返回 m的后继 (由m->m_next指向,可以为空)存放在n中
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
// void MFREE(struct mbuf * m, struct mbuf *n);
/** MFREE(struct mbuf *m, struct mbuf *n)* Free a single mbuf and associated external storage.* Place the successor, if any, in n.*/
#ifdef notyet
#define MFREE(m, n) \{ MBUFLOCK(mbstat.m_mtypes[(m)->m_type]--;) \if ((m)->m_flags & M_EXT) { \if ((m)->m_ext.ext_free) \(*((m)->m_ext.ext_free))((m)->m_ext.ext_buf, \(m)->m_ext.ext_size); \else \MCLFREE((m)->m_ext.ext_buf); \} \(n) = (m)->m_next; \FREE((m), mbtypes[(m)->m_type]); \}
#else /* notyet */
#define MFREE(m, nn) \{ MBUFLOCK(mbstat.m_mtypes[(m)->m_type]--;) \if ((m)->m_flags & M_EXT) { \MCLFREE((m)->m_ext.ext_buf); \} \(nn) = (m)->m_next; \FREE((m), mbtypes[(m)->m_type]); \}
#endif
MGETHDR
分配一个mbuf,并把它初始化为一个分组首部。这个宏与MGET相似,但设置了标志M_PKTHDR,并且数据指针m_data指向紧接着分组首部后的100字节的缓冲
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
// void MGETHDR(struct mbuf * m, int nowait, int type);
#define MGETHDR(m, how, type) { \MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \if (m) { \(m)->m_type = (type); \MBUFLOCK(mbstat.m_mtypes[type]++;) \(m)->m_next = (struct mbuf *)NULL; \(m)->m_nextpkt = (struct mbuf *)NULL; \(m)->m_data = (m)->m_pktdat; \(m)->m_flags = M_PKTHDR; \} else \(m) = m_retryhdr((how), (type)); \
}
MH_ALIGN
设置包含一个分组首部的mbuf的m_data,在这个mbuf数据区的尾部为一个长度为len字节的对象提供空间。这个数据指针也是长字对准方式的
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
/** As above, for mbufs allocated with m_gethdr/MGETHDR* or initialized by M_COPY_PKTHDR.*/
#define MH_ALIGN(m, len) \{ (m)->m_data += (MHLEN - (len)) &~ (sizeof(long) - 1); }
//void MH_ALIGN(struct mbuf * m, int len);M_PREPEND
在m指向的mbuf中的数据前面添加len字节的数据。
如果mbuf有空间,则仅把指针(m_data)减len字节,讲讲长度m_len增加len字节。
如果没有足够的分开,就分配一个新的mbuf,它的m_next指针被设置为m。一个新的mbuf指针存放在m中,并且新mbuf的数据指针被设置,这样len字节的数据被放置在mbuf的尾部。如果一个新mbu被分配,并且原来的mbuf的分组首部标志被设置,则分组首部从老mbuf中移到新mbuf中
// 4.4BSD-Lite\usr\src\sys\sys\mbuf.h
//void M_PREPEND(struct mbuf * m, int len, int nowait);
/** Arrange to prepend space of size plen to mbuf m.* If a new mbuf must be allocated, how specifies whether to wait.* If how is M_DONTWAIT and allocation fails, the original mbuf chain* is freed and m is set to NULL.*/
#define M_PREPEND(m, plen, how) { \if (M_LEADINGSPACE(m) >= (plen)) { \(m)->m_data -= (plen); \(m)->m_len += (plen); \} else \(m) = m_prepend((m), (plen), (how)); \if ((m) && (m)->m_flags & M_PKTHDR) \(m)->m_pkthdr.len += (plen); \
}m_adj
从m指向的mbuf中移除len字节的数据。如果len是整数,则所操作的是紧排在这个mbuf的开始的len字节的数据;负责是紧排在这个mbuf的尾部的len绝对值字节的数据
void m_adj(struct mbuf *mp;, int req_len);
{int len = req_len;struct mbuf *m;count;if ((m = mp) == NULL)return;if (len >= 0) {/** Trim from head.*/while (m != NULL && len > 0) {if (m->m_len <= len) {len -= m->m_len;m->m_len = 0;m = m->m_next;} else {m->m_len -= len;m->m_data += len;len = 0;}}m = mp;if (mp->m_flags & M_PKTHDR)m->m_pkthdr.len -= (req_len - len);} else {/** Trim from tail. Scan the mbuf chain,* calculating its length and finding the last mbuf.* If the adjustment only affects this mbuf, then just* adjust and return. Otherwise, rescan and truncate* after the remaining size.*/len = -len;count = 0;for (;;) {count += m->m_len;if (m->m_next == (struct mbuf *)0)break;m = m->m_next;}if (m->m_len >= len) {m->m_len -= len;if (mp->m_flags & M_PKTHDR)mp->m_pkthdr.len -= len;return;}count -= len;if (count < 0)count = 0;/** Correct length for chain is "count".* Find the mbuf with last data, adjust its length,* and toss data from remaining mbufs on chain.*/m = mp;if (m->m_flags & M_PKTHDR)m->m_pkthdr.len = count;for (; m; m = m->m_next) {if (m->m_len >= count) {m->m_len = count;break;}count -= m->m_len;}while (m = m->m_next)m->m_len = 0;}
}
m_cat
··
Net/3联网数据结构小结
- 只有一个头指针的mbuf链的链表。mbuf链表通过每个链的第一个mbuf的m_nextpkt值连接起来。如下图

顶部的每个mbuf形成这个队列中的第一个记录,下面的三个mbuf形成这个队列的第二个记录。对与一个基于记录的协议,比如UDP,我们在每个队列中能遇到多个记录,但对于像TCP这样的协议,它没有记录的边界,每个队列中只能发现一个记录。
把一个mbuf追加到队列的第一个记录中要遍历所有第一个记录的mbuf,直到遇到m_next为空的mbuf。而追加一个包含新记录的mbuf链到这个队列中,要查找所有记录直到遇到m_nextpkt为空的记录。
- 一个有头指针和尾指针的mbuf链的链表。如2-22。它和2-21中仅有的一点改变:增加了一个尾指针,来简化增加一个新纪录的操作

- 双向循环链表

在这个链表中元素不是mbuf------它是一些定时了两个相邻的指针的结构;一个next指针跟着一个previous指针。两个指针必须在结构的起始处。如果链表为空,表头的next和previous都指向这个表头的本身
m_copy和簇引用计数
使用簇的一个明显好处是在要求包含大量数据时能够减少mbuf的数目。
//4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c
这是m_copym的三参数版本,它隐含的第 4个参数的值为M_DONTWAIT
struct mbuf * m_copy(struct mbuf *m, int offset, int len)创建一个新的mbuf链表,并从m指向的mbuf链表的开始offset处复制len字节的数据。一个新 mbuf链表的指针作为此函数的返回值。如果 len等于常量M_COPYALL,则从这
个mbuf链表的offset开始的所有数据都将被复制。
struct mbuf *m_copym(struct mbuf *m, int offset, int len, int nowait);
另一个好处是多个mbuf间可以共享一个簇。看个例子
-
假设应用程序执行一个write,把4096字节写到TCP插口中。假设插口发送缓存原来是空的,接收插口至少由4096,则会发生如下操作。插口层把前2048字节的数据放在一个簇中,并调用协议的发送例程。TCP发送例程把这个mbuf追加到它的发送缓存后,如下图所示,并调用tcp_output。结构socket中包括sockbuf结构,这个结构中存储着发送缓存mbuf链的链表的表头:so_snd.sb_mb

-
假设这个连接的一个TCP最大报文段大小为1460,tcp_output建立一个报文段来发送包含前1460字节的数据。它还建立一个包含IP和TCP首部的mbuf,为链路层首部预留了空间,并将这个mbuf链传给IP输出。在接口输出队列尾部的mbuf链显示在图2-25中。

-
TCP是一个可靠协议,它必须维护一个发送数据的副本,直到数据被对方确认。本例中,tcp_output调用函数m_copy,请求复制1046字节的数据,从发送缓存起始位置开始。但由于数据被存放在一个簇中,m_copy创建一个mbuf(上图的右下侧)并且对它进行初始化,将它执行那个已存在的簇的正确位置(此例是簇的起始处)。
-
上图的右下侧我们还显示了这个mbuf包含一个分组首部,但它并不是链中的第一个mbuf。当m_copy复制一个包含一个分组首部的mbuf并且从原来的mbuf的起始位置开始复制是,分组首部也被复制下来。因为这个mbuf不是链中的第一个mbuf,这个额外的分组首部被忽略。而在这个额外的分组首部中的m_pkthdr.len的值2048也被忽略。
-
这个共享的簇避免了从内核将数据从一个mbuf复制到另一个mbuf中------这节约了很多开销。它是通过为每个簇提供一个引用计数来实现的,每次另一个mbuf指向这个簇时计数加1,当一个簇释放时计数减1。仅当引用计数为0时,被这个簇占用的存储器才能被其他程序使用
-
比如,当上图底部的mbuf链到达以太网设备驱动程序并且它的内容已经被复制给了这个设备时,驱动程序调用m_freem。这个函数释放带有协议首部的第一个mbuf,并注意到链中第二个mbuf指向一个簇。簇引用计数减1,但由于它的值变成了1,它仍然保存在存储器中,它不能被释放,因为它仍在TCP发送缓存中。
void m_freem(struct mbuf *m)
{struct mbuf *n;if (m == NULL)return;do {MFREE(m, n);} while (m = n);
}// //4.4BSD-Lite\usr\src\sys\kern\uipc_mbuf.c总结
mbuf主要用途是在进程和网络接口之间传递用户数据时用来存放数据数据,但mbuf还用于保存其他的数据:源地址和目的地址、插口选项等
根据M_PKTHAD和M_EXT标识是否被设置,分为四种类型的mbuf
- 无分组首部,mbuf本身带有0-108字节的数据
- 有分组首部,mbuf本身带有0-100字节的数据
- 无分组首部,数据在簇(外部缓存中)
- 有分组首部,数据在簇(外部缓存中)
m_devget,很多网络设备驱动程序调用它来存储一个收到的帧;m_pullup,所有输入例程调用它把协议首部连续放置在一个mbuf中
由一个mbuf指向的簇能通过m_copy被共享。比如,用于TCP输出,因为一个被传输的数据的副本要被发送端保存,直到数据被对方确认。比起进行物理复制来说,通过引用计数,共享簇提高了性能