


企业软件的分类有哪些|app小程序定制开发
企业软件的分类有哪些|app小程序定制开发 企业软件是指为了满足企业运营和管理需求而开发的软件系统。根据不同的功能和应用领域,企业软件可以分为以下几个分类: 1. 企业资源计划(Enterprise Resource Planning,ERP)软…...
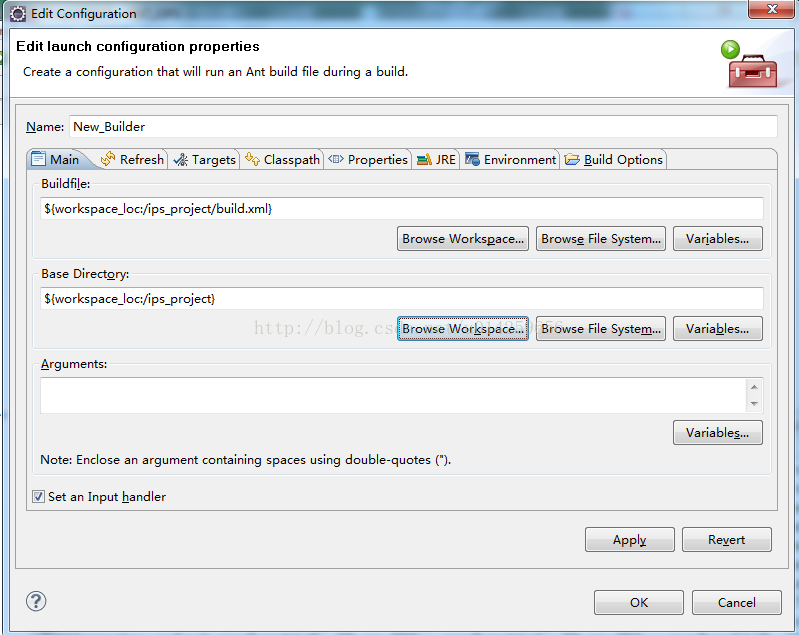
eclipse自动执行ant实行热部署
优点:有很多情况是使用ant脚本编译war包发布到JBOSS中或者其他web server中,比如我修改一个页面文件的话,还需要重新打包,或者每一次执行ant的build脚本,对ant脚本实行热部署点击保存即可自动执行编译,部署…...

用Python实行七段数码管
源码如下: 运行结果如下:...

用Python实行九九乘法
源码如下: 输出结果如下:...
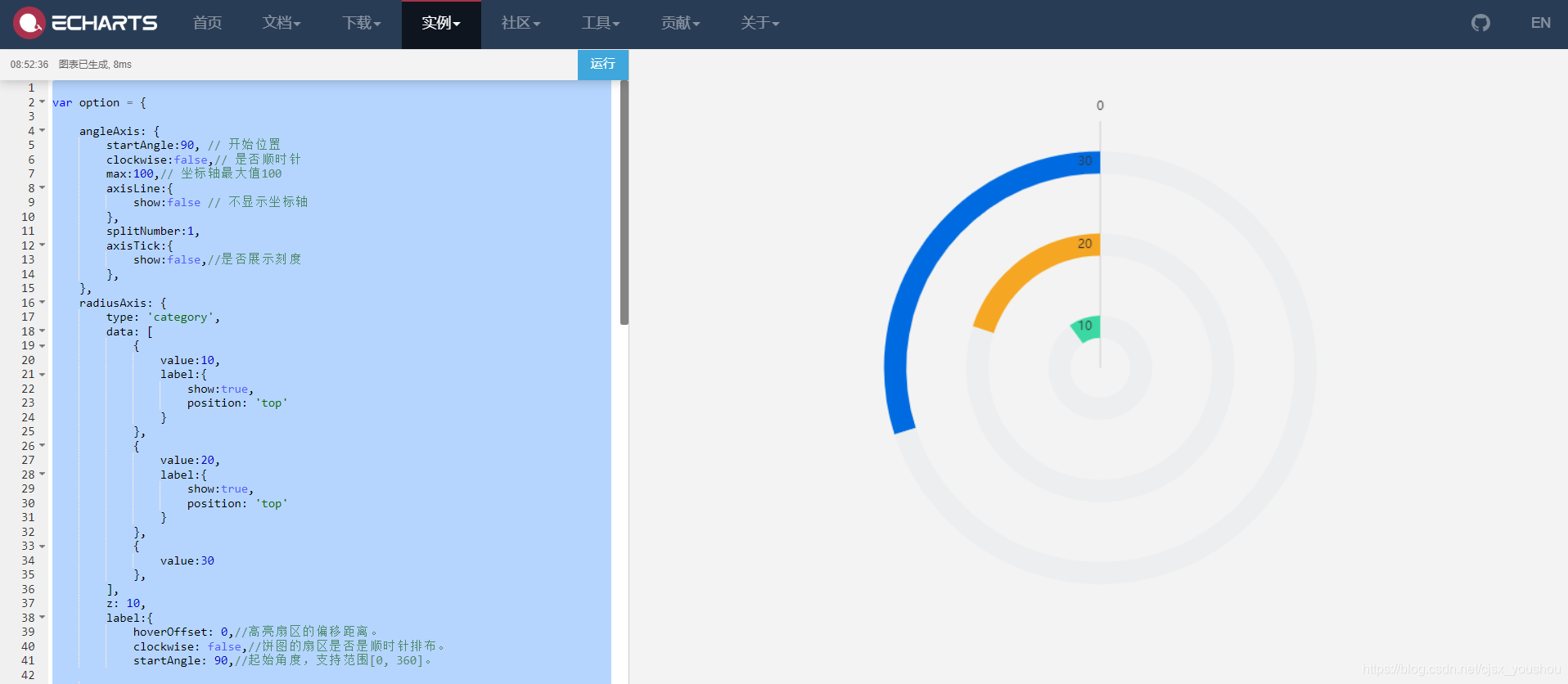
echarths 使用环形柱状图实行环比效果
echarths 使用环形柱状图实行环比效果 var option {angleAxis: {startAngle:90, // 开始位置clockwise:false,// 是否顺时针max:100,// 坐标轴最大值100axisLine:{show:false // 不显示坐标轴},splitNumber:1,axisTick:{show:false,//是否展示刻度},},radiusAxis: {type: cate…...

张雪峰为什么敢实行4天工作制,做到敢为天下先
前言 提起张雪峰,相信大家一定不会陌生,很多人熟知他都是因为他“考研名师”的身份,但是他其实还有另一个身份却鲜少有人知道。 张雪峰还是一家名为“峰学蔚来教育科技有限公司”的老板,公司成立于2021年,位于江苏省…...
axios qs
终于明白了vue使用axios发送post请求时的坑及解决原理 前言:在做项目的时候正好同事碰到了这个问题,问为什么用axios在发送请求的时候没有成功,请求不到数据,反而是报错了,下图就是报错请求本尊 vue里代码如下&#x…...

深入理解qs库:简化你的工作流程
前言 在 vue 开发中,处理 url 查询字符串是一个常见的任务。qs 库是一个流行的工具,可以帮助我们轻松地处理 url 查询字符串的编码和解码。本文将介绍 qs 库的基本用法,并结合实例演示帮助你更好地理解和应用这个实用的工具。 一、qs 是什么&…...
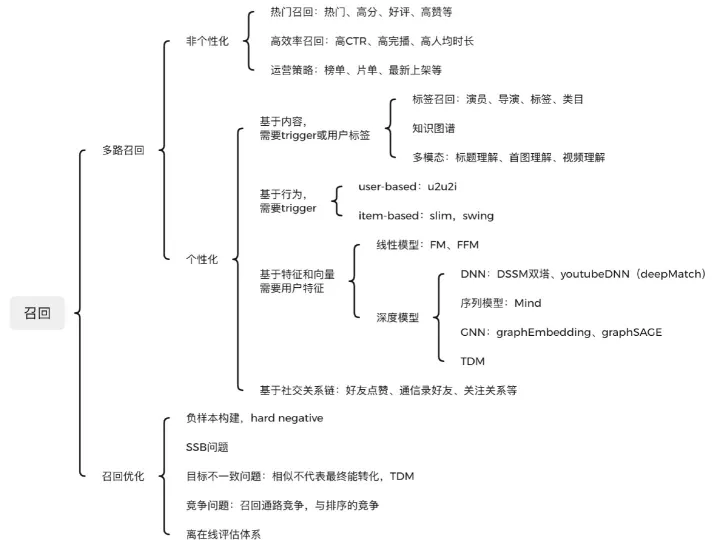
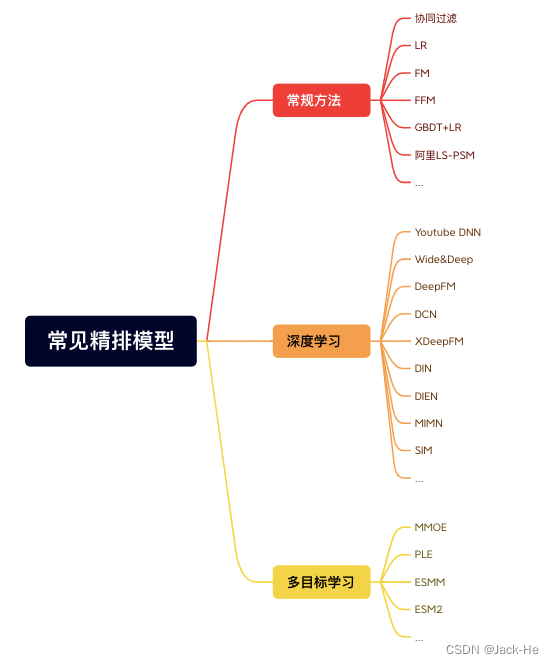
推荐算法架构 :召回(1)
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。召回通…...
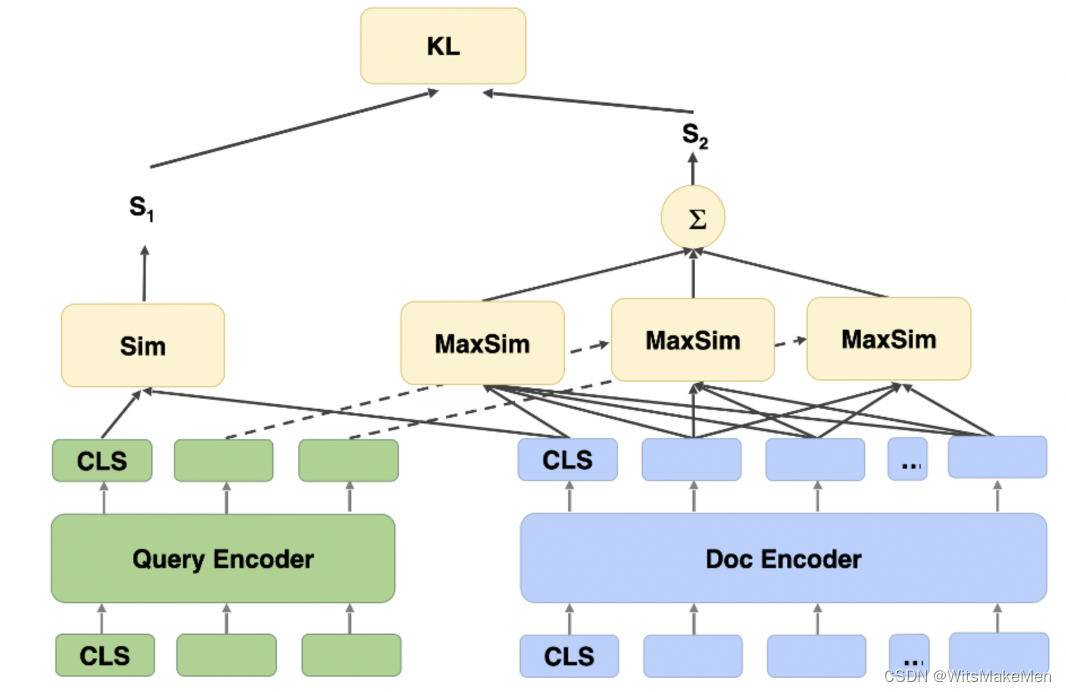
浅谈互联网搜索之召回
一、背景 在搜索系统中,一般会把整个搜索系统划分为召回和排序两大子系统。本文会从宏观上介绍召回系统,并着重介绍语义召回。谨以此文,希望对从事和将要从事搜索行业的工作者带来一些启发与思考。 二、搜索系统召回方法 不同于推荐系统&…...
召回与排序算法总结
尊敬的读者您好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须注明本文出处并附上本文地址超链接以及博主博客地址:https://blog.csdn.net/vensmallzeng。若觉得本文对您有益处还请帮忙点个赞鼓励一下…...

个性化召回
导读:召回几乎是所有推荐系统的基础模块,对应到电商的推荐中,它的作用是从海量的商品池中,筛选出一部分用户可能感兴趣的商品作为上层排序系统的候选集。因此,可以说召回效果的好坏直接决定了推荐效果的上界。 常见的…...
推荐系统之召回
由于毕业后应该会从事召回的工作,而自己之前研究的并不是这个方向,所以对推荐系统中的召回进行简单的学习。 前言 召回就是从海量的类目库中挑选出相似的类目,后续由排序算法对这些类目排序,接着将其推荐给用户,也就是…...

pikache靶场通关——CSRF攻击
文章目录 前言使用工具第一关(host:192.168.1.107)、CSRF(get) loginStep.1、以受害者身份登录账号Step.2、以受害者身份点击修改个人信息的按钮Step.3、以黑客身份使用burp进行抓包(查看对面修改格式)Step4、以黑客身…...
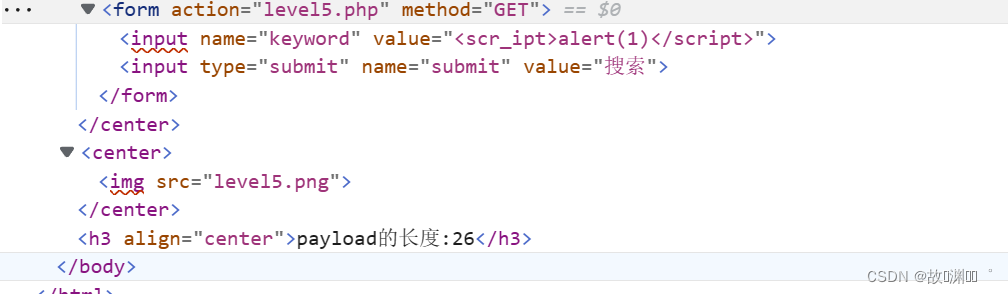
XSS基础——xsslabs通关挑战
目录 XSS基础一、XSS基础概念1、XSS基础概念2、XSS分类 二、xsslabs通关挑战level 1level 2level 3htmlspecialchars函数html事件属性 level 4level 5level 6level 7level 8深入理解浏览器解析机制和XSS向量编码 level 9level 10level 11level 12level 13 三、总结 XSS基础 一…...
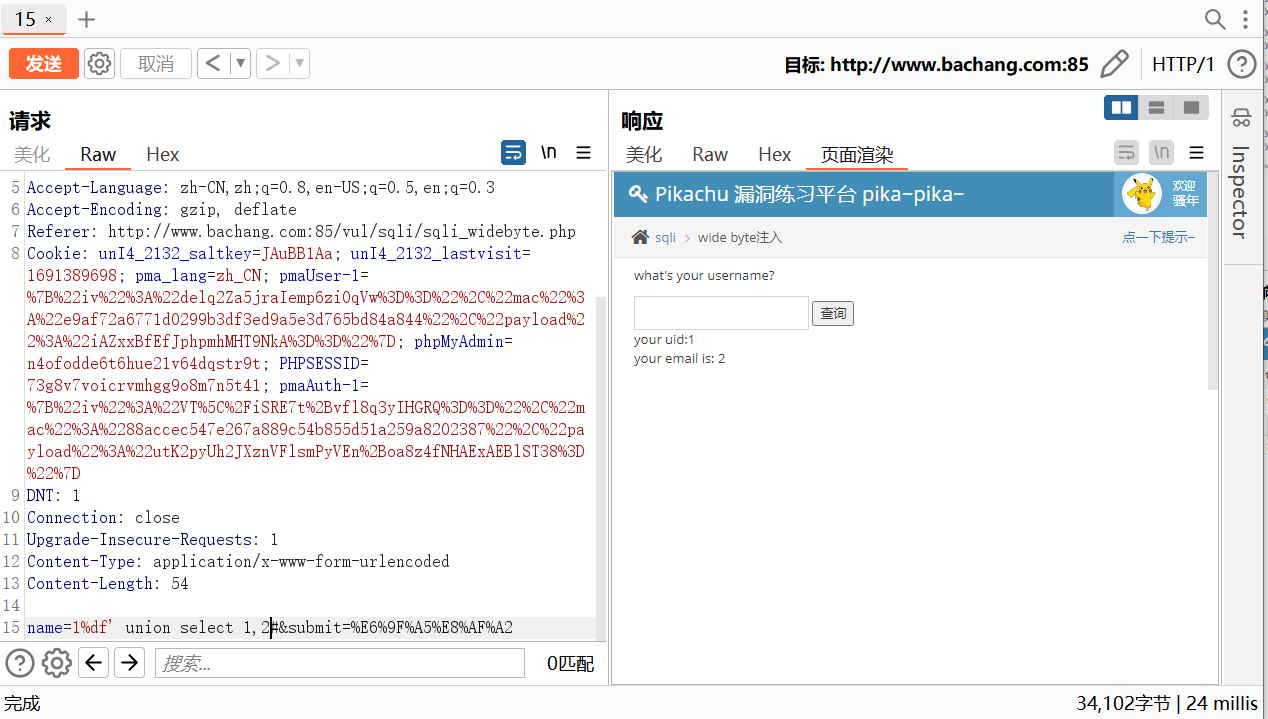
SQL注入-Pikachu靶场通关
SQL注入-Pikachu靶场通关 目录 SQL注入-Pikachu靶场通关概述数字型注入(post)字符型注入(get)搜索型注入xx型注入insert/update注入delete注入http头部注入基于boolian的盲注基于时间的盲注wide byte注入(宽字节注入) 概述 在owasp发布的top10排行榜里&a…...
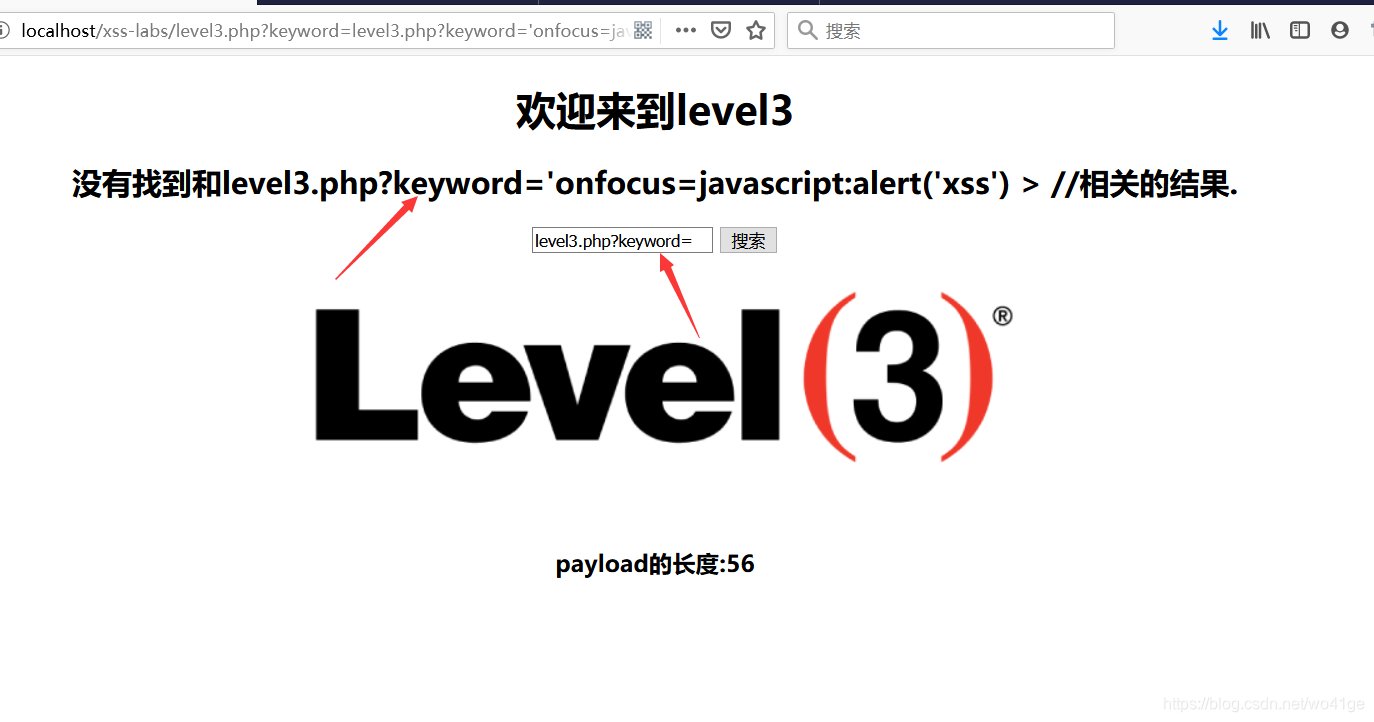
xss-labs通关大合集
漏洞原理,看这里哇 目录 xss-labslevel1level2level3level4level5level6level7level8level9level10level11level12level13level1415关level16level17level18level19Flash产生的xss问题主要有两种方式:常见的可触发xss的危险函数有:xss-labs 文章所用的xss-labs靶场的项目地…...
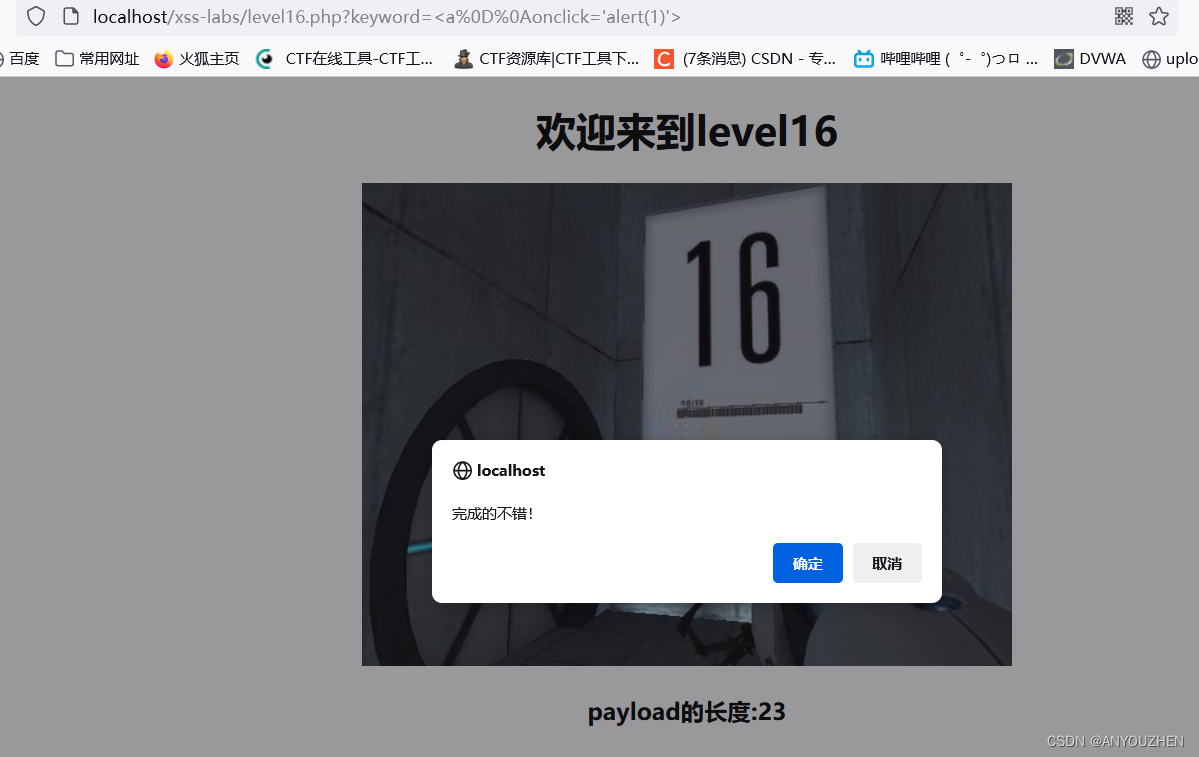
XSS靶场通关
XSS(跨站脚本攻击)是指恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。 XSS按照利用方式主要分为:反射型XSS、存储型XSS、…...
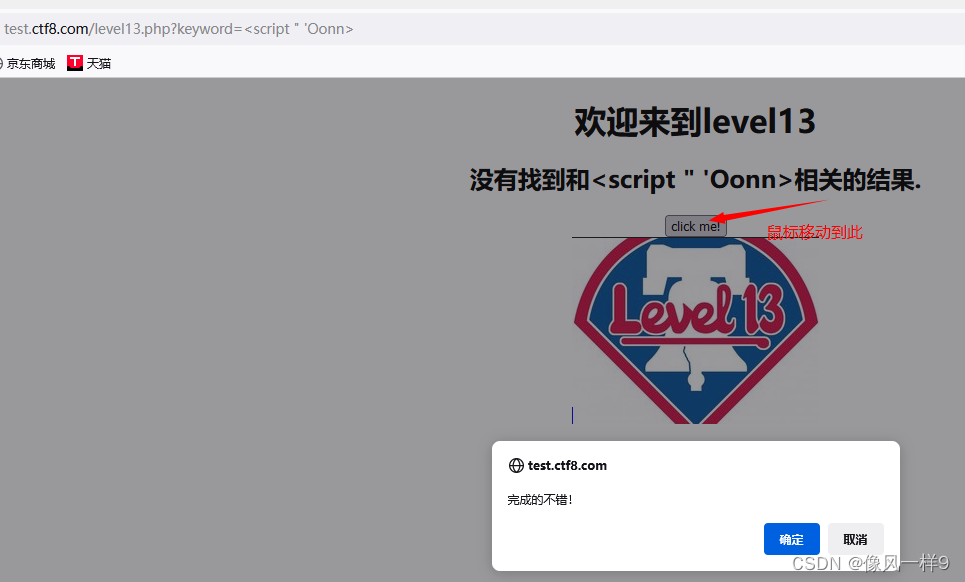
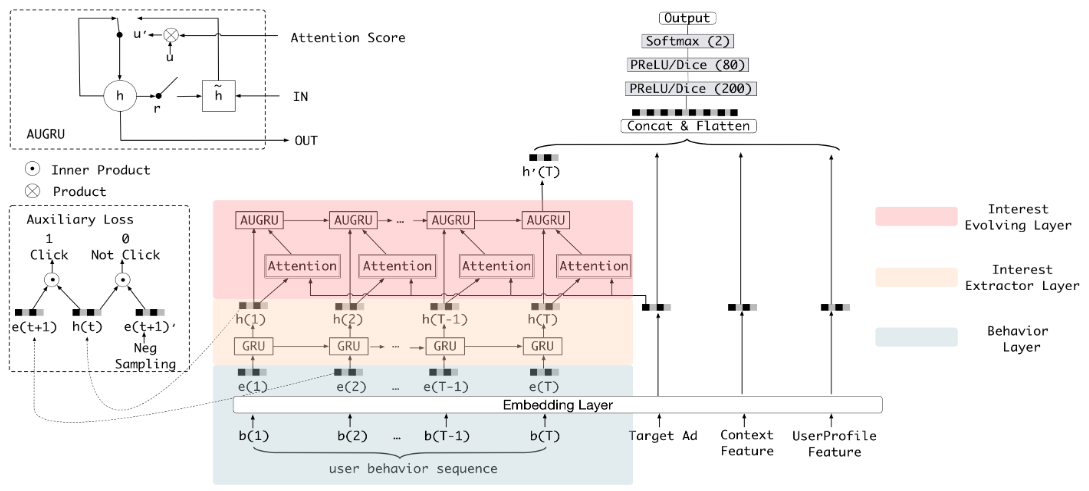
【XSS漏洞-05】XSS-labs靶场通关大挑战
目录 1 实验简介2 XSS通关过程2.0 通关前注意2.1 关卡12.2 关卡22.3 关卡32.4 关卡42.5 关卡52.6 关卡62.7 关卡72.8 关卡82.9 关卡92.10 关卡102.11 关卡112.12 关卡122.13 关卡13 3 总结 1 实验简介 实验网站/靶场:http://test.ctf8.com/。 实验目的:…...

小程序备案和icp备案有什么区别
小程序备案和ICP备案是两种不同的备案类型,它们在备案对象和备案范围上有所不同。 1. 备案对象: - 小程序备案:小程序备案适用于在微信小程序平台上开发并发布的小程序。 - ICP备案:ICP备案适用于在公网上发布的网站&#x…...